
Some time ago, my bed fell apart, and I entered into a dispute with my landlord. “You broke the bed,” he insisted, “so you will have to pay for a new one.”
Being a poor grad student, I wasn’t about to let him have his way. “No, I didn’t break the bed,” I replied. “The bed broke.”

Above: My sad and broken bed. Did it break, or did I break it?
What am I implying here? It’s interesting how this argument relies on a crucial semantic difference between the two sentences:
- I broke the bed
- The bed broke
The difference is that (1) means I caused the bed to break (eg: by jumping on it), whereas (2) means the bed broke by itself (eg: through normal wear and tear).
This is intuitive to a native speaker, but maybe not so obvious why. One might guess from this example that any intransitive verb when used transitively (“X VERBed Y”) always means “X caused Y to VERB“. But this is not the case: consider the following pair of sentences:
- I attacked the bear
- The bear attacked
Even though the syntax is identical to the previous example, the semantic structure is quite different. Unlike in the bed example, sentence (1) cannot possibly mean “I caused the bear to attack”. In (1), the bear is the one being attacked, while in (2), the bear is the one attacking something.
 Above: Semantic roles for verbs “break” and “attack”.
Above: Semantic roles for verbs “break” and “attack”.
Sentences which are very similar syntactically can have different structures semantically. To address this, linguists assign semantic roles to the arguments of verbs. There are many semantic roles (and nobody agrees on a precise list of them), but two of the most fundamental ones are Agent and Patient.
- Agent: entity that intentionally performs an action.
- Patient: entity that changes state as a result of an action.
- Many more.
The way that a verb’s syntactic arguments (eg: Subject and Object) line up with its semantic arguments (eg: Agent and Patient) is called the verb’s argument structure. Note that an agent is not simply the subject of a verb: for example, in “the bed broke“, the bed is syntactically a subject but is semantically a patient, not an agent.
Computational linguists have created several corpora to make this information accessible to computers. Two of these corpora are VerbNet and FrameNet. Let’s see how a computer would be able to understand “I didn’t break the bed; the bed broke” using these corpora.

Above: Excerpt from VerbNet entry for the verb “break”.
VerbNet is a database of verbs, containing syntactic patterns where the verb can be used. Each entry contains a mapping from syntactic positions to semantic roles, and restrictions on the arguments. The first entry for “break” has the transitive form: “Tony broke the window“.
Looking at the semantics, you can conclude that: (1) the agent “Tony” must have caused the breaking event, (2) something must have made contact with the window during this event, (3) the window must have its material integrity degraded as a result, and (4) the window must be a physical object. In the intransitive usage, the semantics is simpler: there is no agent that caused the event, and no instrument that made contact during the event.
The word “break” can take arguments in other ways, not just transitive and intransitive. VerbNet lists 10 different patterns for this word, such as “Tony broke the piggy bank open with a hammer“. This sentence contains a result (open), and also an instrument (a hammer). The entry for “break” also groups together a list of words like “fracture”, “rip”, “shatter”, etc, that have similar semantic patterns as “break”.

Above: Excerpt from FrameNet entry for the verb “break”.
FrameNet is a similar database, but based on frame semantics. The idea is that in order to define a concept, you have to define it in terms of other concepts, and it’s hard to avoid a cycle in the definition graph. Instead, it’s sometimes easier to define a whole semantic frame at once, which describes a conceptual situation with many different participants. The frame then defines each participant by what role they play in the situation.
The word “break” is contained in the frame called “render nonfunctional“. In this frame, an agent affects an artifact so that it’s no longer capable of performing its function. The core (semantically obligatory) arguments are the agent and the artifact. There are a bunch of optional non-core arguments, like the manner that the event happened, the reason that the agent broke the artifact, the time and place it happened, and so on. FrameNet tries to make explicit all of the common-sense world knowledge that you need to understand the meaning of an event.
Compared to VerbNet, FrameNet is less concerned with the syntax of verbs: for instance, it does not mention that “break” can be used intransitively. Also, it has more fine-grained categories of semantic roles, and contains a description in English (rather than VerbNet’s predicate logic) of how each semantic argument participates in the frame.
An open question is: how can computers use VerbNet and FrameNet to understand language? Nowadays, deep learning has come to dominate NLP research, so that VerbNet and FrameNet are often seen as relics of a past era, when people still used rule-based systems to do NLP. It turned out to be hard to use VerbNet and FrameNet to make computers do useful tasks.
But recently, the NLP community is realizing that deep learning has limitations when it comes to common-sense reasoning, that you can’t solve just by adding more layers on to BERT and feeding it more data. So maybe deep learning systems can benefit from these lexical semantic resources.


 Above: Global Coronavirus stats on March 23, 2020, when the S&P 500 reached its lowest point during the pandemic (
Above: Global Coronavirus stats on March 23, 2020, when the S&P 500 reached its lowest point during the pandemic (

 Table of pairwise agreement (adapted from Table 5.2 of Bram’s thesis)
Table of pairwise agreement (adapted from Table 5.2 of Bram’s thesis)










 . The assumption is the initial cluster assignments are mostly correct, but we can still refine them to be more distinct and separated.
. The assumption is the initial cluster assignments are mostly correct, but we can still refine them to be more distinct and separated. to the cluster centroids
to the cluster centroids 
 (the degrees of freedom), so the above can be simplified to:
(the degrees of freedom), so the above can be simplified to:

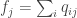 is the soft cluster frequency of cluster j. Intuitively, squaring
is the soft cluster frequency of cluster j. Intuitively, squaring 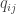 draws the probability distribution closer to the centroids.
draws the probability distribution closer to the centroids.


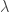 to balance the two terms:
to balance the two terms:

