
The Internet is a great invention. Just about everything in humanity’s knowledge can be found on the Internet: with just a few keystrokes, you can find dozens of excellent quality textbooks, YouTube videos and blog posts about any topic you want to learn. The information is accessible to a degree that scholars and inventors could have hardly dreamed of even a few decades ago. With the popularity of remote work and everything moving online this decade, it is not surprising that many people are eager to learn new skills from the Internet.
However, despite the abundance of resources, self-studying over the Internet is harder than you think. You can easily find a list of resources on your topic, full of courses and textbooks to study from (like this one for theoretical physics). This knowledge is, in theory, enough to make you an expert, if only you were able to go through it all.
The problem is that internet self-study tends to be a passive activity. Humans cannot learn new skills effectively by only passively absorbing knowledge, we learn by doing. Ideally, 70% of your time should be active practice, trying to do the skill and learning from experience, and maybe 30% of the time on passively reading to expand your theoretical and background knowledge. You can’t learn to ski just by reading books and watching tutorials about it, at some point, you will need to actually put on a pair of skis and head to the mountains.
Some skills are relatively straightforward to actively practice using only a computer. Learning to program, for example: you can build a fully functional website with just a laptop and all the tools you need are available for free on the Internet. If you want to learn music production, everything can be done in software, and you need only a modest budget to buy some equipment. If you want to learning digital marketing, just set up an ecommerce website and play around with some Google ad campaigns, and you are good to go.
But many skills cannot be done using just a computer, in which case self-studying over the Internet is much more difficult. If you want to study chemistry, you can’t just set up a lab in your house and start playing around with chemicals. When the subject requires institutional resources to participate actively, this makes it difficult to self-study. In some cases it’s not even clear what counts as “actively” doing it, like studying philosophy or literature.
The situation is not hopeless, though. What you need to do is try to make it as an active process as possible. Here I will talk about some strategies I have used to learn more actively.
If possible, learn by doing it. Obvious, but worth reiterating one more time. Even for activities done on the computer, it is very tempting to passively consume content about it instead of actively practicing. Many music production students watch hours of tutorials about how to use various plugins and their features, instead of working on producing a song.
This is human nature, we are lazy creatures and passively consuming content is much easier than doing. It feels like we are learning something, but if we don’t put the knowledge to use, we’ll quickly forget it. If your skill requires some modest investment in tools and equipment to start doing, it is well worth it since you will learn much faster.
Do the exercises. Many textbooks and courses come with exercises to help you practice. In some fields, like mathematics, the standard way of learning is by doing lots of exercises. And in most university courses, much of your grade come from assignments that you hand in.
In practice, though, I’ve found it difficult to get enough motivation to do exercises properly, when I know that nobody is going to read it, and the experience is not very satisfying. Also, with nobody to check your answers, you don’t know if you did it incorrectly. But even a few exercises are better than not doing any at all, and anyhow the first few are the most valuable since you get diminishing returns the more exercises you do.
Discuss with others. The ideal situation is if you know somebody who is more experienced than you in the activity, then you can meet with them periodically to discuss what you are learning (and buy them a lunch for the favor). If you can find a friend who is not an expert but is interested in learning the same subject together, that is helpful as well. Even if they are at the same level as you, they’ll uncover some knowledge gaps that you missed and vice-versa.
Take online lessons. A hack that I’ve used on numerous occasions when I don’t know anybody who knows the topic I’m learning is buying an expert’s time via online lessons. For learning languages, I like Italki, a platform where you pay hourly for lessons with a native speaker. There are platforms where you can schedule lessons on a variety of topics, or buy consulting sessions with an expert.
The most effective way to use online lessons is to come prepared with a list of questions, or ask for feedback on something you attempted to do. In my Italki sessions, what I often do is write a passage of text in Spanish, and during the lesson, have my teacher correct it for mistakes in grammar and phrasing. It’s important to do this because otherwise, many teachers will simply regurgitate lesson material that they prepared in advance, which is no better than just watching a YouTube video.
Write blog posts. This is one of the best ways to actively learn and can be applied to any subject. It is effective because it will be visible to the public, so you will naturally make a serious effort to do it properly (much more than when doing throwaway exercises). I write blog post because I prefer the written medium; some people prefer to make YouTube videos which has a similar effect.
One limitation is that you can get it completely wrong, unwillingly spread misinformation, and nobody will notice or care enough to correct you. In other cases, readers have contacted me to correct errors on my blog post, which is helpful for improving the content (albeit not so helpful for my learning if it has been several years since I wrote it and I’ve already forgotten all the details).
Write book reviews. It is a lot of effort to write a blog post, and recently, not something that I’ve done that often. Instead, a lower effort version that I’ve been doing is writing a book review blog where I write a short summary and review of every book that I read. These are relatively quick to write since I’m just summarizing the main points of a book that I’ve just read (and is fresh on my mind), and I’m not trying to think of something original to say like for my blog posts, yet writing it is still somewhat of an active process.






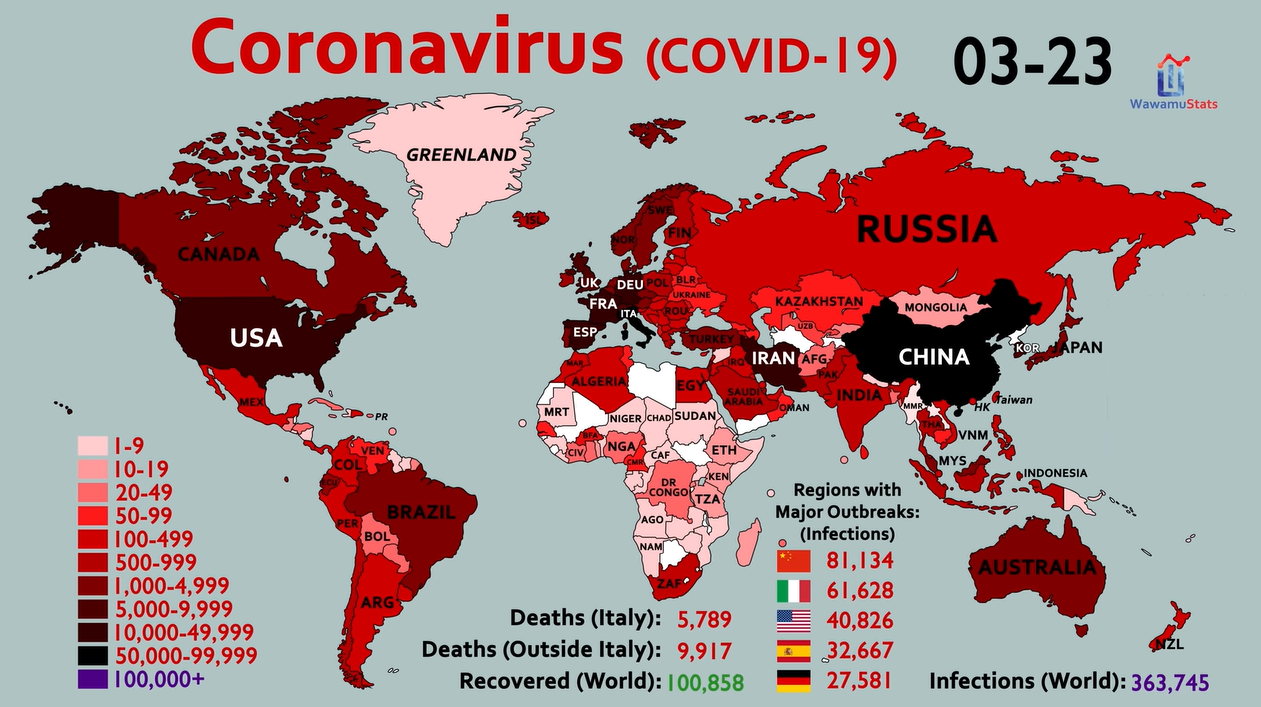 Above: Global Coronavirus stats on March 23, 2020, when the S&P 500 reached its lowest point during the pandemic (
Above: Global Coronavirus stats on March 23, 2020, when the S&P 500 reached its lowest point during the pandemic (


