
Deep autoencoders are a good way to learn representations and structure from unlabelled data. There are many variations, but the main idea is simple: the network consists of an encoder, which converts the input into a low-dimensional latent vector, and a decoder, which reconstructs the original input. Then, the latent vector captures the most essential information in the input.
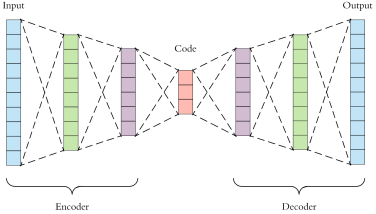
Above: Diagram of a simple autoencoder (Source)
One of the uses of autoencoders is to discover clusters of similar instances in an unlabelled dataset. In this post, we examine some ways of clustering with autoencoders. That is, we are given a dataset and K, the number of clusters, and need to find a low-dimensional representation that contains K clusters.
Problem with Naive Method
An naive and obvious solution is to take the autoencoder, and run K-means on the latent points generated by the encoder. The problem is that the autoencoder is only trained to reconstruct the input, with no constraints on the latent representation, and this may not produce a representation suitable for K-means clustering.

Above: Failure example with naive autoencoder clustering — K-means fails to find the appropriate clusters
Above is an example from one of my projects. The left diagram shows the hidden representation, and the four classes are generally well-separated. This representation is reasonable and the reconstruction error is low. However, when we run K-means (right), it fails spectacularly because the two latent dimensions are highly correlated.
Thus, our autoencoder can’t trivially be used for clustering. Fortunately, there’s been some research in clustering autoencoders; in this post, we study two main approaches: Deep Embedded Clustering (DEC), and Deep Clustering Network (DCN).
DEC: Deep Embedded Clustering
DEC was proposed by Xie et al. (2016), perhaps the first model to use deep autoencoders for clustering. The training consists of two stages. In the first stage, we initialize the autoencoder by training it the usual way, without clustering. In the second stage, we throw away the decoder, and refine the encoder to produce better clusters with a “cluster hardening” procedure.

Above: Diagram of DEC model (Xie et al., 2016)
Let’s examine the second stage in more detail. After training the autoencoder, we run K-means on the hidden layer to get the initial centroids 
First, we soft-assign each latent point 

In the paper, they fix 

Next, we define an auxiliary distribution P by:

where 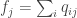
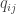

Above: The auxiliary distribution P is derived from Q, but more concentrated around the centroids
Finally, we define the objective to minimize as the KL divergence between the soft assignment distribution Q and the auxiliary distribution P:

Using standard backpropagation and stochastic gradient descent, we can train the encoder to produce latent points
DCN: Deep Clustering Network
DCN was proposed by Yang et al. (2017) at around the same time as DEC. Similar to DEC, it initializes the network by training the autoencoder to only reconstruct the input, and initialize K-means on the hidden representations. But unlike DEC, it then alternates between training the network and improving the clusters, using a joint loss function.

Above: Diagram of DCN model (Yang et al., 2017)
We define the optimization objective as a combination of reconstruction error (first term below) and clustering error (second term below). There’s a hyperparameter 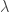

This function is complicated and difficult to optimize directly. Instead, we alternate between fixing the clusters while updating the network parameters, and fixing the network while updating the clusters. When we fix the clusters (centroid locations and point assignments), then the gradient of L with respect to the network parameters can be computed with backpropagation.
Next, when we fix the network parameters, we can update the cluster assignments and centroid locations. The paper uses a rolling average trick to update the centroids in an online manner, but I won’t go into the details here. The algorithm as presented in the paper looks like this:

Comparisons and Further Reading
To recap, DEC and DCN are both models to perform unsupervised clustering using deep autoencoders. When evaluated on MNIST clustering, their accuracy scores are comparable. For both models, the scores depend a lot on initialization and hyperparameters, so it’s hard to say which is better.
One theoretical disadvantage of DEC is that in the cluster refinement phase, there is no longer any reconstruction loss to force the representation to remain reasonable. So the theoretical global optimum can be achieved trivially by mapping every input to the zero vector, but this does not happen in practice when using SGD for optimization.
Recently, there have been lots of innovations in deep learning for clustering, which I won’t be covering in this post; the review papers by Min et al. (2018) and Aljalbout et al. (2018) provide a good overview of the topic. Still, DEC and DCN are strong baselines for the clustering task, which newer models are compared against.
References
- Xie, Junyuan, Ross Girshick, and Ali Farhadi. “Unsupervised deep embedding for clustering analysis.” International conference on machine learning. 2016.
- Yang, Bo, et al. “Towards k-means-friendly spaces: Simultaneous deep learning and clustering.” Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.
- Min, Erxue, et al. “A survey of clustering with deep learning: From the perspective of network architecture.” IEEE Access 6 (2018): 39501-39514.
- Aljalbout, Elie, et al. “Clustering with deep learning: Taxonomy and new methods.” arXiv preprint arXiv:1801.07648 (2018).


 Above: Encoder-decoder image captioning neural network (Figure 1 of paper)
Above: Encoder-decoder image captioning neural network (Figure 1 of paper) Above: Training procedure for caption LSTM, given known image and caption
Above: Training procedure for caption LSTM, given known image and caption Above: Inference procedure for caption LSTM, given only the image but no caption
Above: Inference procedure for caption LSTM, given only the image but no caption Above: How I felt when I got this working
Above: How I felt when I got this working “A train is on the tracks at a station”
“A train is on the tracks at a station” “A woman is holding a cat in her arms”
“A woman is holding a cat in her arms” “A little girl holding a stuffed animal in her hand”
“A little girl holding a stuffed animal in her hand” “A baby laying on a bed with a stuffed animal”
“A baby laying on a bed with a stuffed animal” “A dog is running with a frisbee in its mouth”
“A dog is running with a frisbee in its mouth” Above: Only when everything is correct will you get positive results; many things can cause a model to fail. (
Above: Only when everything is correct will you get positive results; many things can cause a model to fail. (
 Above: A Long Short Term Memory (LSTM) network handles long term dependencies by adding a memory cell (
Above: A Long Short Term Memory (LSTM) network handles long term dependencies by adding a memory cell ( Above: Komodo Dragon, Indonesia
Above: Komodo Dragon, Indonesia Above: Sample spectrograms of “yes” and “no”
Above: Sample spectrograms of “yes” and “no” Above: A Convolutional Neural Network (LeNet). VGG16 is similar, but has even more layers.
Above: A Convolutional Neural Network (LeNet). VGG16 is similar, but has even more layers.