
In my previous post on the Teochew dialect, I noted that Teochew has a complex system of tone sandhi. The last syllable of a word keeps its citation (base) form, while all preceding syllables undergo sandhi. For example:
gu5 (cow) -> gu1 nek5 (cow-meat = beef)
seng52 (play) -> seng35 iu3 hi1 (play a game)
The sandhi system is quite regular — for instance, if a word’s base tone is 52 (falling tone), then its sandhi tone will be 35 (rising tone), across many words:
toin52 (see) -> toin35 dze3 (see-book = read)
mang52 (mosquito) -> mang35 iu5 (mosquito-oil)
We can represent this relationship as an edge in a directed graph 52 -> 35. Similarly, words with base tone 5 have sandhi tone 1, so we have an edge 5 -> 1. In Teochew, the sandhi graph of the six non-checked tones looks like this:
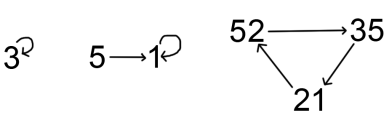
Above: Teochew tone sandhi, Jieyang dialect, adapted from Xu (2007). For simplicity, we ignore checked tones (ending in -p, -t, -k), which have different sandhi patterns.
This type of pattern is not unique to Teochew, but exists in many dialects of Min Nan. Other dialects have different tones but a similar system. It’s called right-dominant chain-shift, because the rightmost syllable of a word keeps its base tone. It’s also called a “tone circle” when the graph has a cycle. Most notably, the sandhi pattern where A -> B, and B -> C, yet A !-> C is quite rare cross-linguistically, and does not occur in any Chinese dialect other than in the Min family.
Is there any explanation for this unusual tone sandhi system? In this blog post, I give an overview of some attempts at an explanation from theoretical phonology and historical linguistics.
Xiamen tone circle and Optimality Theory
The Xiamen / Amoy dialect is perhaps the most studied variety of Min Nan. Its sandhi system looks like this:

Barrie (2006) and Thomas (2008) attempt to explain this system with Optimality Theory (OT). In modern theoretical phonology, OT is a framework that describes how the underlying phonemes are mapped to the output phonemes, not using rules, but rather with a set of constraints. The constraints dictate what kinds of patterns that are considered “bad” in the language, but some violations are worse than others, so the constraints are ranked in a hierarchy. Then, the output is the solution that is “least bad” according to the ranking.
To explain the Xiamen tone circle sandhi, Thomas begins by introducing the following OT constraints:
- *RISE: incur a penalty for every sandhi tone that has a rising contour.
- *MERGE: incur a penalty when two citation tones are mapped to the same sandhi tone.
- DIFFER: incur penalty when a base tone is mapped to itself as a sandhi tone.
Without any constraints, there are 5^5 = 3125 possible sandhi systems in a 5-tone language. With these constraints, most of the hypothetical systems are eliminated — for example, the null system (where every tone is mapped to itself) incurs 5 violations of the DIFFER constraint.
These 3 rules aren’t quite enough to fully explain the Xiamen tone system: there are still 84 hypothetical systems that are equally good as the actual system. With the aid of a Perl script, Thomas then introduces more rules until only one system (the actual observed one) emerges as the best under the constraints.
Problems with the OT explanation
There are several reasons why I didn’t find this explanation very satisfying. First, it’s not falsifiable: if your constraints don’t generate the right result, you can keep adding more and more constraints, and tweak the ranking, until they produce the result you want.
Second, the constraints are very arbitrary and lack any cognitive-linguistic motivation. You can explain the *MERGE constraint as trying to preserve contrasts, which makes sense from an information theory point of view, but what about DIFFER? It’s unclear why base tones shouldn’t be mapped to the same sandhi tone, especially since many languages (like Cantonese) manage fine with no sandhi at all.
Even considering Teochew, which is more closely related to the Xiamen dialect, we see that all three constraints are violated. I’m not aware of any analysis of Teochew sandhi using OT, and it would be interesting to see, but surely it would have a very different set of constraints from the Xiamen system.
Nevertheless, OT has been an extremely successful framework in modern phonology. In some cases, OT can describe a pattern very cleanly, where you’d need very complicated rules to describe them. In that case, the set of OT constraints would be a good explanation for the pattern.
Also, if the same constraint shows up in a lot of languages, then that increases its credibility that it’s a true cross-language tendency, rather than a just a made-up rule to explain the data. For example, if the *RISE constraint shows up in OT grammars for many languages, then you could claim that there’s a general tendency for languages to prefer falling tones over rising tones.
Evidence from Middle Chinese
Chen (2000) gives a different perspective. Essentially, he claims that it’s impossible to make sense of the data in any particular modern-day dialect. Instead, we should compare multiple dialects together in the context of historical sound changes.
The evidence he gives is from the Zhangzhou dialect, located about 40km inland from Xiamen. The Zhangzhou dialect has a similar tone circle as Xiamen, but with different values!

It’s not obvious how the two systems are related, until you consider the mapping to Middle Chinese tone categories:

The roman numerals I, II, III denote tones of Middle Chinese, spoken during ~600AD. Middle Chinese had four tones, but none of the present day Chinese dialects retain this system, after centuries of tone splits and merges. In many dialects, a Middle Chinese tone splits into two tones depending on whether the initial is voiced or voiceless. When comparing tones from different dialects, it’s often useful to refer to historical tone categories like “IIIa”, which roughly means “syllables that were tone III in Middle Chinese and the initial consonant is voiceless”.
It’s unlikely that both Xiamen and Zhangzhou coincidentally developed sandhi patterns that map to the same Middle Chinese tone categories. It’s far more likely that the tone circle developed in a common ancestral language, then their phonetic values diverged afterwards in the respective present-day dialects.
That still leaves open the question of: how exactly did the tone circle develop in the first place? It’s likely that we’ll never know for sure: the details are lost to time, and the processes driving historical tone change are not very well understood.
In summary, theoretical phonology and historical linguistics offer complementary insights that explain the chain-shift sandhi patterns in Min Nan languages. Optimality Theory proposes tendencies for languages to prefer certain structures over others. This partially explains the pattern; a lot of it is simply due to historical accident.
References
- Barrie, Michael. “Tone circles and contrast preservation.” Linguistic Inquiry 37.1 (2006): 131-141.
- Chen, Matthew Y. Tone sandhi: Patterns across Chinese dialects. Vol. 92. Cambridge University Press, 2000. Pages 38-49.
- Thomas, Guillaume. “An analysis of Xiamen tone circle.” Proceedings of the 27th West Coast Conference on Formal Linguistics. Cascadilla Proceedings Project, Somerville, MA. 2008.
- Xu, Hui Ling. “Aspect of Chaozhou grammar: a synchronic description of the Jieyang variety.” (2007).
