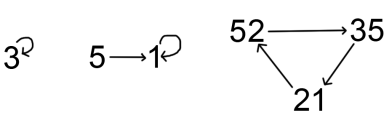I’ve had a few opportunities to work with NLP in Chinese. English and Chinese are very different languages, yet generally the same techniques apply to both. But there is one source of frustration that comes up from time to time, and it’s perhaps not what you’d expect.
The difficulty is that Chinese doesn’t put words between spaces. Soallyourwordsarejumbledtogetherlikethis.
“Okay, that’s fine,” you say. “We’ll just have to run a tokenizer to separate apart the words before we do anything else. And here’s a neural network that can do this with 93% accuracy (Qi et al., 2020). That should be good enough, right?”
Well, kind of. Accuracy here isn’t very well-defined because Chinese people don’t know how to segment words either. When you ask two native Chinese speakers to segment a sentence into words, they only agree about 90% of the time (Wang et al., 2017). Chinese has a lot of compound words and multi-word expressions, so there’s no widely accepted definition of what counts as a word. Some examples: 吃饭,外国人,开车,受不了. It is also possible (but rare) for a sentence to have multiple segmentations that mean different things.
Arguably, word boundaries are ill-defined in all languages, not just Chinese. Hapselmath (2011) defined 10 linguistic criteria to determine if something is a word (vs an affix or expression), but it’s hard to come up with anything consistent. Most writing systems puts spaces in between words, so there’s no confusion. Other than Chinese, only a handful of other languages (Japanese, Vietnamese, Thai, Khmer, Lao, and Burmese) have this problem.
Word segmentation ambiguity causes problems in NLP systems when different components expect different ways of segmenting a sentence. Another way the problem can appear is if the segmentation for some human-annotated data doesn’t match what a model expects.
Here is a more concrete example from one of my projects. I’m trying to get a language model to predict a tag for every word (imagine POS tagging using BERT). The language model uses SentencePiece encoding, so when a word is out-of-vocab, it gets converted into multiple subword tokens.
“expedite ratification of the proposed law”
=> [“expedi”, “-te”, “ratifica”, “-tion”, “of”, “the”, “propose”, “-d”, “law”]
In English, a standard approach is to use the first subword token of every word, and ignore the other tokens, like this:

This doesn’t work in Chinese — because of the word segmentation ambiguity, the tokenizer might produce tokens that span across multiple of our words:

So that’s why Chinese is sometimes headache-inducing when you’re doing multilingual NLP. You can work around the problem in a few ways:
- Ensure that all parts of the system uses a consistent word segmentation scheme. This is easy if you control all the components, but hard when working with other people’s models and data though.
- Work on the level of characters and don’t do word segmentation at all. This is what I ended up doing, and it’s not too bad, because individual characters do carry semantic meaning. But some words are unrelated to their character meanings, like transliterations of foreign words.
- Do some kind of segment alignment using Levenshtein distance — see the appendix of this paper by Tenney et al. (2019). I’ve never tried this method.
One final thought: the non-ASCII Chinese characters surprisingly never caused any difficulties for me. I would’ve expected to run into encoding problems occasionally, as I had in the past, but never had any character encoding problems with Python 3.
References
- Haspelmath, Martin. “The indeterminacy of word segmentation and the nature of morphology and syntax.” Folia linguistica 45.1 (2011): 31-80.
- Qi, Peng, et al. “Stanza: A python natural language processing toolkit for many human languages.” Association for Computational Linguistics (ACL) System Demonstrations. 2020.
- Tenney, Ian, et al. “What do you learn from context? Probing for sentence structure in contextualized word representations.” International Conference on Learning Representations. 2019.
- Wang, Shichang, et al. “Word intuition agreement among Chinese speakers: a Mechanical Turk-based study.” Lingua Sinica 3.1 (2017): 13.