
Lately I’ve been learning my girlfriend’s dialect of Chinese, called the Teochew dialect. Teochew is spoken in the eastern part of the Guangdong province by about 15 million people, including the cities of Chaozhou, Shantou, and Jieyang. It is part of the Min Nan (闽南) branch of Chinese languages.
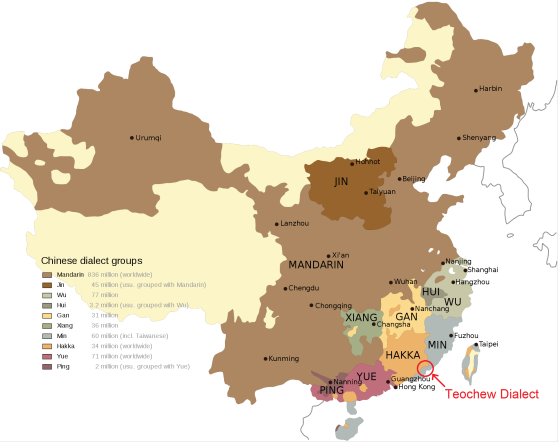
Above: Map of major dialect groups of Chinese, with Teochew circled. Teochew is part of the Min branch of Chinese. Source: Wikipedia.
Although the different varieties of Chinese are usually refer to as “dialects”, linguists consider them different languages as they are not mutually intelligible. Teochew is not intelligible to either Mandarin or Cantonese speakers. Teochew and Mandarin diverged about 2000 years ago, so today they are about as similar as French is to Portuguese. Interestingly, linguists claim that Teochew is one of the most conservative Chinese dialects, preserving many archaic words and features from Old Chinese.
Above: Sample of Teochew speech from entrepreneur Li Ka-shing.
Since I like learning languages, naturally I started learning my girlfriend’s native tongue soon after we started dating. It helped that I spoke Mandarin, but Teochew is not close enough to simply pick up by osmosis, it still requires deliberate study. Compared to other languages I’ve learned, Teochew is challenging because very few people try to learn it as a foreign language, thus there are few language-learning resources for it.
Writing System
The first hurdle is that Teochew is primarily spoken, not written, and does not have a standard writing system. This is the case with most Chinese dialects. Almost all Teochews are bilingual in Standard Chinese, which they are taught in school to read and write.
Sometimes people try to write Teochew using Chinese characters by finding the equivalent Standard Chinese cognates, but there are many dialectal words which don’t have any Mandarin equivalent. In these cases, you can invent new characters or substitute similar sounding characters, but there’s no standard way of doing this.
Still, I needed a way to write Teochew, to take notes on new vocabulary and grammar. At first, I used IPA, but as I became more familiar with the language, I devised my own romanization system that captured the sound differences.
Cognates with Mandarin
Note (Jul 2020): People in the comments have pointed out that some of these examples are incorrect. I’ll keep this section the way it is because I think the high-level point still stands, but these are not great examples.
Knowing Mandarin was very helpful for learning Teochew, since there are lots of cognates. Some cognates are obviously recognizable:
- Teochew: kai shim, happy. Cognate to Mandarin: kai xin, 开心.
- Teochew: ing ui, because. Cognate to Mandarin: ying wei, 因为
Some words have cognates in Mandarin, but mean something slightly different, or aren’t commonly used:
- Teochew: ou, black. Cognate to Mandarin: wu, 乌 (dark). The usual Mandarin word is hei, 黑 (black).
- Teochew: dze: book. Cognate to Mandarin: ce, 册 (booklet). The usual Mandarin word is shu, 书 (book).
Sometimes, a word has a cognate in Mandarin, but sound quite different due to centuries of sound change:
- Teochew: hak hau, school. Cognate to Mandarin: xue xiao, 学校.
- Teochew: de, pig. Cognate to Mandarin: zhu, 猪.
- Teochew: dung: center. Cognate to Mandarin: zhong, 中.
In the last two examples, we see a fairly common sound change, where a dental stop initial (d- and t-) in Teochew corresponds to an affricate (zh- or ch-) in Mandarin. It’s not usually enough to guess the word, but serves as a useful memory aid.
Finally, a lot of dialectal Teochew words (I’d estimate about 30%) don’t have any recognizable cognate in Mandarin. Examples:
- da bo: man
- no gya: child
- ge lai: home
Grammatical Differences
Generally, I found Teochew grammar to be fairly similar to Mandarin, with only minor differences. Most grammatical constructions can transfer cognate by cognate and still make sense in the other language.
One significant difference in Teochew is the many fused negation markers. Here, a syllable starts with the initial b- or m- joined with a final to negate something. Some examples:
- bo: not have
- boi: will not
- bue: not yet
- mm: not
- mai: not want
- ming: not have to
Phonology and Tone Sandhi
The sound structure of Teochew is not too different from Mandarin, and I didn’t find it difficult to pronounce. The biggest difference is that syllables may end with a stop: -t, -k, -p, and -m, whereas Mandarin syllables can only end with a vowel or nasal. The characteristic of a Teochew accent in Mandarin is replacing /f/ with /h/, and indeed there is no /f/ sound in Teochew.
The hardest part of learning Teochew for me were the tones. Teochew has either six or eight tones depending on how you count them, which isn’t difficult to produce in isolation. However, Teochew has a complex system of tone sandhi rules, where the tone of each syllable changes depending on the tone of the following syllable. Mandarin has tone sandhi to some extent (for example, the third tone sandhi rule where nǐ + hǎo is pronounced níhǎo rather than nǐhǎo). But Teochew takes this to a whole new level, where nearly every syllable undergoes contextual tone change.
Some examples (the numbers are Chao tone numerals, with 1 meaning lowest and 5 meaning highest tone):
- gu5: cow
- gu1 nek5: beef
Another example, where a falling tone changes to a rising tone:
- seng52: to play
- seng35 iu3 hi1: to play a game
There are tables of tone sandhi rules describing in detail how each tone gets converted to what other tone, but this process is not entirely regular and there are exceptions. As a result, I frequently get the tone wrong by mistake.
Update: In this blog post, I explore Teochew tone sandhi in more detail.
Resources for Learning Teochew
Teochew is seldom studied as a foreign language, so there aren’t many language learning resources for it. Even dictionaries are hard to find. One helpful dictionary is Wiktionary, which has the Teochew pronunciation for most Chinese characters.
Also helpful were formal linguistic grammars:
- Xu, Huiling. “Aspects of Chaoshan grammar: A synchronic description of the Jieyang dialect.” Monograph Series Journal of Chinese Linguistics 22 (2007).
- Yeo, Pamela Yu Hui. “A sketch grammar of Singapore Teochew.” (2011).
The first is a massively detailed, 300-page description of Teochew grammar, while the second is a shorter grammar sketch on a similar variety spoken in Singapore. They require some linguistics background to read. Of course, the best resource is my girlfriend, a native speaker of Teochew.
Visiting the Chaoshan Region
After practicing my Teochew for a few months with my girlfriend, we paid a visit to her hometown and relatives in the Chaoshan region. More specifically, Raoping County located on the border between Guangdong and Fujian provinces.


Left: Chaoshan railway station, China. Right: Me learning the Gongfu tea ceremony, an essential aspect of Teochew culture.
Teochew people are traditional and family oriented, very much unlike the individualistic Western values that I’m used to. In Raoping and Guangzhou, we attended large family gatherings in the afternoon, chatting and gossiping while drinking tea. Although they are still Han Chinese, the Teochew consider themselves a distinct subgroup within Chinese, with their unique culture and language. The Teochew are especially proud of their language, which they consider to be extremely hard for outsiders to learn. Essentially, speaking Teochew is what separates “ga gi nang” (roughly translated as “our people”) from the countless other Chinese.
My Teochew is not great. Sometimes I struggle to get the tones right and make myself understood. But at a large family gathering, a relative asked me why I was learning Teochew, and I was able to reply, albeit with a Mandarin accent: “I want to learn Teochew so that I can be part of your family”.

Above: Me, Elaine, and her grandfather, on a quiet early morning excursion to visit the sea. Raoping County, Guangdong Province, China.
Thanks to my girlfriend Elaine Ye for helping me write this post. Elaine is fluent in Teochew, Mandarin, Cantonese, and English.


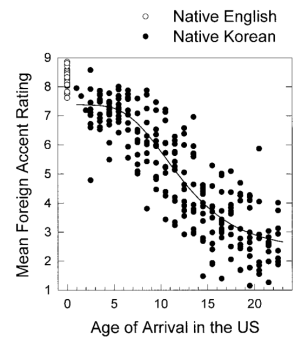 Above: Scores for phonological task decrease as age of arrival increases, but even very early arrivals retain a non-native accent.
Above: Scores for phonological task decrease as age of arrival increases, but even very early arrivals retain a non-native accent. Above: Scores for grammatical task only start to decrease after about age 7.
Above: Scores for grammatical task only start to decrease after about age 7.







