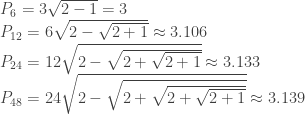The name of the hackathon was Code B: UW Algorithmic Trading Competition. It was hosted by Bloomberg and various UW student groups. It’s a 17 hour hackathon where you “create the best trading platform completely from scratch”. As far as I know, this is the first time the hackathon has been run, and in this article I’m going to write about my experience.

We were allowed teams of up to three, but my roommate Andrei and I signed up as a team of two. Like myself, Andrei is also a CS major. Neither of us had any experience with trading stocks, or anything finance related, for that matter. When asked to choose a team name, we named ourselves team /dev/rand (implying that we were so bad that we’d be no better than a random number generator)
The hackathon was scheduled to start Friday evening, running through the night until noon the next day. The goal was to write a program to autonomously trade stocks over a 20 minute period, battling other programs to earn as much money as possible. The programs communicated by connecting to a central server on Bloomberg’s side, so we could use any programming language we wanted. It was decided that Andrei would come up with strategies, and I would implement them in Python.
Rules of the Game
The specifics of the API and mechanics of the game were not revealed until the official start of the hackathon. The 50-60 teams packed into an auditorium as the organizers started to explain the technical details.
The rules turned out to be fairly simple. The only actions allowed were to bid (attempt to purchase) on a stock for some price, or ask (attempt to sell) a stock for some price. If at any point someone’s bid is higher than someone else’s ask, the deal goes through and the stock changes hands.
Now all of this was fairly standard, but after this part, the rules diverged from real life. In order to encourage people to buy stocks (and not just hoard the initial money), each share of a stock paid dividends to its owner every second. And to prevent simply buying one stock and holding it for the entire duration, the dividends given out quickly diminishes the longer you own the stock.
This quirky dividends system turned out to be central to our strategy. Additionally, the differences from real stock markets meant that any previous experience with finance and stock trading was less useful — definitely a good thing for us because many of our competitors were seriously studying finance and we had no experience anyway.
And it begins!
After the rules presentation, the hackathon kicked off. It was slightly past 7pm, and very quickly you could see teams buying and selling stocks. We decided to take it slow, discussing strategies over dinner.
We started work around 8pm. I began writing code to parse the input, while Andrei worked on deciphering the rather cryptic specifications document. Although API specs were clear enough, they were (intentionally) vague about how the system behaved behind the scenes. There were many formulas with lots of variables, many of which we had no idea what they meant.
So we took an experimental approach. Tentatively we put in a bid for a few shares of Google stock — and our net worth immediately took a nosedive. But the stock rapidly generated dividends, and before long, our net worth recovered to what it was initially, and it kept on going up! The success was short lasted, however, as quickly the dampening effects of the dividends started to kick in, and our rate of return quickly diminished to near zero.
We tried again, buying a few shares of the Twitter stock. The same thing happened — our value went down, quickly recovered, then gradually leveled to 50 dollars more than we started with.
With this information, we formulated a rough strategy. We didn’t know how to predict which stocks will go up; neither did we have a plan for buying and selling stocks at a favorable rate. Instead, we would take advantage of a stock’s “golden period”, where the stock initially pays massive dividends. It was crucial to buy as quickly as possible, since the clock started ticking as soon as you own one share of the stock. So we use all our money to buy as many shares of the stock as possible, doesn’t matter what price. Now we wait as the golden period payout multiplied by our entire bankroll makes us rich. Then, a few minutes later, when the golden period runs out, we would slowly sell, iteratively lowering our asking price until we found a buyer.
Once we sold the last share of a stock, the dividend clock doesn’t immediately reset, it slowly regenerates. So if we wait a while, say 5 minutes, then buy back the stock, we get another brief golden period. Taking this one step further, we decided on a strategy that cycled through the 10 stocks: at any given point, we would hold at most 4 of them, while the other 6 were left to “recharge”.
I proceeded to code the algorithm, while Andrei analyzed the spec document and brainstormed ways to improve the strategy. From the equations in the spec, he came up with a formula to determine what stock generated the highest dividends. Every half hour, the scoreboard would reset, and by 3am, I was basically done, and our algorithm consistently came either first or second by the end of each round. Our algorithm worked beautifully, simultaneously juggling a bunch of different stocks, some buying, others slowly selling. We watched the scoreboard as we earned hundreds of dollars every minute, ending with a ridiculous amount of money by the time it reset.
It seemed at this point that a lot of the teams were having implementation issues, like connecting to the network and parsing input, and only a handful were making any money at all, so I was pretty happy with our results.
But at 4am, disaster struck. A new round started, and our algorithm instantly plummeted to the bottom of the leaderboard. Every time we bought or sold anything, we lost money, and none of it was coming back through dividends. What happened?? It turns out that the parameters were changed, so that a very low amount of dividends were paid for owning a stock, and the only profits were made by buying low and selling high. This meant that our whole strategy, which centered around maximizing dividends, was rendered useless.
What’s worse — I discovered a bug in my implementation where our stocks were not being cycled properly: it would sell a certain stock, then instantly buy back the same stock, which didn’t allow the dividends clock to reset, meaning no dividends. Also, by this point a lot of teams were flooding the network with requests, making any network call have a small chance of throwing an exception and crashing the whole thing entirely.
The network problem was easy to fix, but at 5am, I was really tired and had difficulty tracking down the bug that was causing it to buy back the same stock. Andrei suggested a new set of strategies for the “low dividends” scenario, but by now, I was too tired to implement another set of strategies. Instead, we tweaked various constants in our program to make it play more patiently and more predictably, so even in the worst case it would make marginal gains instead of finishing dead last. After 2 hours of debugging, we managed to track down the cycling bug.
It was 7am and I could hardly keep my eyes open so we found a couch and napped for two hours, until the mock competition began.
Mock Competition and final tweaking
At 9am, a few hours before the final competition, there was a mock competition which was meant to be identical to the final competition. There were three rounds: a high dividends scenario, a low dividends, and one in the middle.
We won the high dividends round hands down, unsurprisingly as our entire strategy was designed around this set of parameters in mind. In the low dividends round, we didn’t do as well, but thanks to careful tweaking, we still made a modest amount of money, coming in fifth. In the medium round, we got second place. This was enough to win the mock competition.
Now, let me give you a summary of our competition. Most of the teams increased gradually in net worth, with their score slowly increasing as they slowly accumulated dividends. We were confident that we could play the dividends game, so it didn’t trouble us too much. What was really troubling was a team called “vlad” (I don’t quite remember what their name was, but it ended with vlad). Instead of gradually gaining money a few dollars at a time, “vlad” remained at a constant net worth for a long time, then suddenly gain hundreds of dollars instantly. This meant that their algorithm operated completely differently from ours, and we had absolutely no explanation of what was going on.
It didn’t help that the formula for net worth was complicated and we didn’t fully understand it. Our net worth clearly increased when we did well, but it fluctuated wildly, sometimes dipping by hundreds of points when we made a large transaction, only to bounce back when dividends started rolling in.
The next few hours were fairly unproductive, since we had no more ideas on how to improve our algorithm. Although Andrei had some ideas on strategies for the low dividends game, after pulling an all-nighter I was in no shape to try implementing them.
The Final Game
It was soon time for the final competition, the cumulation of all our efforts. Having carefully noted down the parameters for the mock competition, we were ready to use this information to get every edge we could for the finals.
Round 1 was high dividends. We played with a highly aggressive set of parameters, dumping our bad stocks for very cheap in pursuit of the dividends regeneration. The early game was contentious, but by the 10 minute mark, we gained a solid lead over the competition and maintained the lead until the end. We won round 1, with “vlad” coming in third place.
Round 2 was low dividends. We deployed the patient strategy, which was less eager to dump anything, holding onto bad stocks until we get a good price for them, since there were little dividends to fight over anyway. We came fifth place, with “vlad” coming in fourth.
Round 3 was medium dividends. We started off uncertain — at the halfway mark we were still in the middle of the pack — but slowly we gained ground, and five minutes before the end, we were in third position. “vlad” was in first place, with a big enough lead that neither we nor the second place team were going to overtake him. But at this point, we knew that from our points in the first round, we only needed second place to beat “vlad” and win the competition — and with 3 minutes left on the clock, we overtook the second place team. We were going to win it!
Then, the whole scoreboard goes black.
It didn’t crash, no, it was the contest organizers’ tactic to increase suspense so the final winners are not known until the winners are announced. We waited anxiously as the final seconds ticked down, the organizers announcing fourth place, third place, UI award. We just needed second place in this round to win, if we get third place in this round, “vlad” beats us by a hair.
And the second place goes to… team /dev/rand. What? We stared in disbelief as we realize we lost to “vlad”.
Going home
Turns out that in the last 2 minutes of competition, we got overtaken by not one, but two teams. So we actually finished round 3 in fourth place.
Our prize for winning second place? A playstation 4 (worth ~450) and a parrot drone (worth ~100), and most importantly, the satisfaction of winning a finance competition without knowing the first thing about finance. Team “vlad” got two playstations and a drone (well, they could have taken all 3 playstations but they were nice enough to leave us one)
Big thanks to all the organizers and volunteers for keeping everything running smoothly!
If you’re interested, our source code is in a git repo here. It’s 400 lines of hackathon-level-bad python code.
What about real algo trading?
A natural question to ask is, can we get rich IRL with this algorithm? Answer is clearly no — we essentially gamed the system by greedily grabbing the golden period of dividends, a mechanic designed to encourage people to buy and sell stocks. Of course, in the real world, dividends don’t work like that.
Then other than this mechanic, how else is this competition different from real world algo trading? Unfortunately, I don’t know enough about this topic to answer that question.
Philosophically, I still don’t understand how it’s possible that they basically pull money out of thin air. I mean, a stock trader doesn’t intrinsically create value for society, but they get rich doing it? I don’t know.
















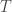 border tiles. If we’re considering every possible configuration, there are
border tiles. If we’re considering every possible configuration, there are 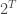 of them. With backtracking, this number is cut down enough for this algorithm to be practical, but we can make one important optimization.
of them. With backtracking, this number is cut down enough for this algorithm to be practical, but we can make one important optimization.
 combinations. With segregation, we only have
combinations. With segregation, we only have 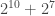 : about a 100x speedup.
: about a 100x speedup.












 rows and
rows and  columns, each cell is given an unique quality rank, as in 1 being the best, 2 being the second best, and
columns, each cell is given an unique quality rank, as in 1 being the best, 2 being the second best, and  being the worst.
being the worst. and
and 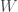 as odd numbers with
as odd numbers with  and
and  , the task is to choose a rectangle of height
, the task is to choose a rectangle of height  ,
, 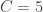 ,
, 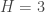 ,
,  :
:
 rectangles in the configuration is the one shown, with a median of 9. Since no
rectangles in the configuration is the one shown, with a median of 9. Since no 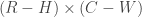 possible positions for the rectangle to be placed, and we will check each of them. Checking for the median requires sorting, which is of complexity
possible positions for the rectangle to be placed, and we will check each of them. Checking for the median requires sorting, which is of complexity  .
.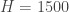 and
and  , this amounts to over 2 million sorts, or many billion operations, which is clearly too much.
, this amounts to over 2 million sorts, or many billion operations, which is clearly too much.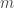 , the smallest median. Let us arbitrarily ‘guess’ a value of
, the smallest median. Let us arbitrarily ‘guess’ a value of 
 grid:
grid:











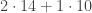 or 38.
or 38.![S = [e_1,e_2, \cdots e_n]](https://s0.wp.com/latex.php?latex=S+%3D+%5Be_1%2Ce_2%2C+%5Ccdots+e_n%5D&bg=ffffff&fg=393939&s=0&c=20201002) such that S is the optimal set for weight W.
such that S is the optimal set for weight W.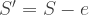
 must be the optimal set for
must be the optimal set for  (I’m going to use the notation
(I’m going to use the notation  to denote the weight of an item e)
to denote the weight of an item e)
 is a function taking a list of items we can use, L, and the minimum weight, W, and returning the minimum cost. e is an element of L (for convenience, e is always the first element).
is a function taking a list of items we can use, L, and the minimum weight, W, and returning the minimum cost. e is an element of L (for convenience, e is always the first element). , we don’t have to dump any more items.
, we don’t have to dump any more items. is the path taken when we decide to dump e.
is the path taken when we decide to dump e. is the path taken when we don’t dump any more of e. In order to avoid recursing indefinitely, once we decide not to dump any more of something we never go back and dump more of it.
is the path taken when we don’t dump any more of e. In order to avoid recursing indefinitely, once we decide not to dump any more of something we never go back and dump more of it.







 . This complexity is not actually polynomial, but this algorithm is considered to run in pseudo-polynomial time.
. This complexity is not actually polynomial, but this algorithm is considered to run in pseudo-polynomial time.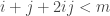 by using two nested for loops:
by using two nested for loops: . The new algorithm:
. The new algorithm: is prime where k can be written as
is prime where k can be written as 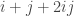 where i and j are integers. We can rewrite this:
where i and j are integers. We can rewrite this:
 and
and  are odd numbers, and any number that can be written as the product of two odd numbers are composite.
are odd numbers, and any number that can be written as the product of two odd numbers are composite. so we are left with the odd prime numbers.
so we are left with the odd prime numbers. operations, while the Sieve of Eratosthenes uses
operations, while the Sieve of Eratosthenes uses  .
. iteratively.
iteratively. sides, if the side length of a polygon with
sides, if the side length of a polygon with  sides is known:
sides is known:
 is a temporary variable, and
is a temporary variable, and  is the side length of an inscribed polygon with
is the side length of an inscribed polygon with 
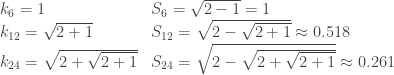
 where
where  is the side length, and
is the side length, and  is the apothem. As the number of sides increases, the apothem becomes closer and closer to the radius, so here we’ll just let
is the apothem. As the number of sides increases, the apothem becomes closer and closer to the radius, so here we’ll just let 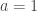 .
. , where
, where 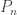 is the area of a polygon with
is the area of a polygon with