
The Sieve of Eratosthenes is probably the best known algorithm for generating primes. Together with wheel factorization and other optimization options, it can generate primes very quickly.
But a lesser well known algorithm for sieving primes is the Sieve of Sundaram. This algorithm was discovered in 1934 by Sundaram; like the sieve of Eratosthenes it finds all prime numbers up to a certain integer.
The algorithm
A simplified version of the algorithm, using N as the limit to which we want to find primes to:
m =: Floor of N/2
L =: List of numbers from 1 to m
For every solution (i,j) to i + j + 2ij < m:
Remove i + j + 2ij from L
For each k remaining in L:
2k + 1 is prime.
In practice we can find solutions to 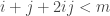
For i in 0 to m:
For j in i to m:
L[i + j + 2ij] =: False
Here i is always less than j, because the two are interchangeable and filtering it twice would be a waste.
We don’t actually need to loop j from 0 to m. From the inequality 
m =: Floor of N/2
L =: Boolean array of length m
Fill L with true
For i in 0 to m:
For j in i to (m-i)/(2i+1):
L[i + j + 2ij] =: False
For each k remaining in L:
2k + 1 is prime.
Why this algorithm works
In the algorithm, 
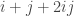

Both 

Of the odd numbers, those that cannot be written as the product of two odd numbers are prime. We’ve filtered everything that can be written as 
This algorithm only gets the odd prime numbers, but fortunately there is only one even prime number, 2.
Benchmarks with the Sieve of Eratosthenes
Here’s an implementation of the Sieve of Sundaram:
#include <stdio.h>
#include <stdlib.h>
typedef unsigned long long ll;
int main() {
ll n = 100000000LL;
ll m = n/2;
char *sieve = malloc(m);
for(ll i=0; i<m; i++)
sieve[i] = 1;
for(ll i=1; i<m; i++)
for(ll j=i; j<=(m-i)/(2*i+1); j++)
sieve[i+j+2*i*j] = 0;
ll s=1;
for(ll i=1; i<m; i++)
if(sieve[i]) s++;
printf("%llu", s);
return 0;
}
This code counts the number of primes below 100 million, which should be 5761455. The above code runs in 9.725 seconds.
Here’s an alternative, an implementation of the more standard Sieve of Eratosthenes:
#include <stdio.h>
#include <stdlib.h>
typedef unsigned long long ll;
int main(){
ll lim = 100000000LL;
char *sieve = malloc(lim);
for(int i=0; i<lim; i++)
sieve[i] = 1;
int s=0;
for(int i=2; i<lim; i++){
if(sieve[i]){
s++;
for(int j=2; j<=lim/i; j++)
sieve[i*j] = 0;
}
}
printf("%d", s);
return 0;
}
I was surprised to find that the Sieve of Eratosthenes actually ran faster. It completed in 7.289 seconds.
I expected the Sieve of Sundaram to be faster because according to Wikipedia this algorithm uses 


Hi there. Interesting reading, I hadn’t come across the Sieve of Sundaram before. (I’ve been doing some Project Euler questions using Groovy so new algorithms of such things are interesting to me as Groovy isn’t the quickest at straight computation and I’m not really a super maths-head.)
There are a few simple ways you can make your implementation faster.
1/ You can use calloc() rather than malloc() to remove the need for the first loop that clears the memory. (You need to reverse the sieve logic too, such that you set value to “1” rather than “0” and use !sieve[i] in the summation loop.)
2/ You can remove the calculation for the max limit for “j” from the for() loop and calculate it only once before the loop.
3/ You can get rid of the complex calculation of the element from the inner loop and just use simple addition instead.
4/ Change the summation loop to use ints rather than long longs.
With these changes I brought the runtime down from 8.51s to 6.49s on my machine, whereas the Sieve of Eratosthenes, as you have implemented it, was taking 9.88s. So it was actually slower than the original Sundaram solution (as you were hoping it to be).
However, it’s possible to make the Sieve of Erastosthenes solution faster too by:
1/ Using the same calloc method.
2/ Removing the counting from the loop making it a vanilla sieve only needing the outer loop to go to SQRT(lim) and using a simple addition for calculating the element to be set, then using a summation loop as per your other solution.
This brought the runtime down from 9.88s to 5.40s, so it was eventually faster than the Sundaram solution!
If you’re interested I can post these amended versions up on my blog. (http://keyzero.wordpress.com)
LikeLike
You’re probably right. I’m not very skilled in the art of optimizing, so I wouldn’t have thought of any of the techniques you mentioned.
Though optimization may improve performance considerably (which is important in real world applications), I’ve found that the algorithm is much more important than the implementation. I’ve never found myself optimizing this way on a Project Euler problem, for example.
I’ve seen some of your Project Euler posts, they’re pretty good!
LikeLike
Absolutely agree. Algorithm is king – this is where the orders of magnitude of savings are to be had. I just learnt my craft on prehistoric machines with clock speeds in the low megahertz and memory measured in kilobytes and I still haven’t got used to just throwing away CPU cycles during implementation!
LikeLike
Hi! Great post, made Sundaram clear for me, thanks.
Considering keyzero’s suggestions and making a point of getting rid of the division, I optimized the loop to
for(ll i=1; ; i++){
ll j = 2*(i+i*i);
if(j >= m) break;
ll inc = 1+2*i;
for( ; j<m; j+=inc)
sieve[j] = 1;
}
With this, the runtime was 1.67s while the Eratosthenes took 2.24s (including keyzero's suggestions).
LikeLike
the sieves of sundaram is my project when i studied it i was intrested
LikeLike
Interesting algorithm.
But take a look at how one can optimize the sieve of Eratosthenes here: http://wwwhomes.uni-bielefeld.de/achim/prime_sieve.html
LikeLike
Pingback: Algorithms: Prime Number Sieves « Carlton Shepherd
I’m also fooling around with some of the project euler problems, thanks for posting this it helped me fix my version.
I found a couple of bugs in your implementation that are evident when you print out your primes. I compared my attempts to the list of the first 10000 at: http://primes.utm.edu/lists/small/10000.txt
1. You don’t start off with numbers being 0, so your code counts ‘1’ and all of the evens as prime. As keyzero points out, use calloc but use ‘0’ instead of 1, that’ll fix that bug (leave the rest of your logic the same). Also, you can start your loop at 2 to avoid counting 1 as a prime.
2. You forgot the final step of multiplying by 2n + 1, so your loop marks as prime a bunch of odd numbers that are composites:
1 3 5 [9] 11 [15] [21] 23 29 [33]
From the wikipedia entry on Sundaram’s sieve: “The remaining numbers are doubled and incremented by one, giving a list of the odd prime numbers (i.e., all primes except 2) below 2n + 2”.
LikeLike
Really? If that is so, that’d be some extremely bad code I wrote … but it seems to work. Are you talking about the implementation or the pseudocode (which is not meant to be run)?
LikeLike
The implementation. It’s pretty easy to see the missing evens and the “1” case just by looking at your implementation code. Add the print statements to see the missing 2n + 1 results too. That last line on the wikipedia page is key.
Sundaram’s sieve, as I understand it, is supposed to be fast because it completely ignores evens, so you have to zero them out yourself (since you’re building a sieve table).
LikeLike
Oh I see what you mean. The code is designed to count how many primes there are below a certain number, so there is obviously no need to multiply by 2 and add 1. Also the 2 being a prime case is dealt with by starting with a counter of 1.
So yes, if you want to generate primes, the modification is fairly trivial. I wouldn’t say that counts as a bug xD
LikeLike
The code makes a table of primes and not primes and then counts the primes. It doesn’t mark evens or 1 as not primes, so there’s no way your code counts the correct number of primes. Worse, it segfaults because the code tries to reference a value outside of the memory you allocated. Those are what we call in the industry as “bugs”. I hope this goads you into making those trivial fixes.
LikeLike
fun(m)=my(L=vector(m,n,[n,n]);for(i=1,sqrtint(m\6),for(j=i,(m-i)\(6*i+1),L[6*i*j+i+j][2]=0;L[6*i*j-i-j][2]=0;L[6*i*j-i+j][1]=0;L[6*i*j-j+i][1]=0));L=fold(concat,apply(r->[6*r[1]-1,6*r[2]+1,L));L=vecsort(L,,8)L[3..#L] PARI/GP with a slightly wrong limit ( you can use select statements to implement it easier). This produces all primes greater than 3 based on a similar relation to the one used by the sieve of sundaram just replacing only looking on the plus side with both, and working mod 6.
LikeLike