
I’ve started doing some of the Facebook engineering puzzles, which are programming challenges that Facebook supposedly uses to recruit people.
This is a little bit similar to Project Euler and various online judges like SPOJ, but it’s somewhat different too.
Instead of submitting solutions in a web form, solutions are sent via email, in the form of an attachment. After several hours, the automated grader would send you back a response: whether it was successful or not, and if it is, how long your program ran.
The Facebook system differs from SPOJ in that results are not available immediately, and also that an incorrect submission would return a generic error message (whether it produced incorrect output, crashed, ran out of time, failed to compile, whatever).
This made it a bit annoying to write solutions as it was difficult to figure out exactly what was wrong with the submission.
The problems are grouped into four groups in order of difficulty: Hors d’oeuvre, Snack, Meal, and Buffet. So far I’ve only solved the Hors d’oeuvre problems and one snack.
User Bin Crash
The problem goes something like this:
You’re on a plane, and somehow you have to dump some cargo or else it will crash. You know how much you need to dump (in pounds), and also an inventory of the items you can dump.
Each item in the inventory has a certain weight, and a certain value. By dumping a combination of the items, you have to dump at minimum the given weight, while minimizing the loss.
You can only dump integral amounts of an item (you can’t dump three quarters of a package), but you’re allowed to dump any amount of the item.
The program you write takes the parameters and outputs the minimum loss (value of items that are dumped).
An example
Suppose that the plane needs to dump 13 pounds. To simplify things, suppose that there are only two types of items we are allowed to dump.
Item A weighs 5 pounds, and costs 14.
Item B weighs 3 pounds, and costs 10.
The optimal solution is to dump two of item A, and one of item B. The cost for this is 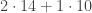
Any other combination either costs more than 38, or does not weigh at least 13 pounds.
A solution using dynamic programming
This problem is a variation of the fairly well known knapsack problem. A dynamic programming solution exists for that, and can be modified to work for this problem.
Dynamic programming is just a way to speed up recursion. So in order to form a dynamic programming algorithm, we should first make a recursive algorithm.
Working backwards, suppose that we have a weight W, and a set of items ![S = [e_1,e_2, \cdots e_n]](https://s0.wp.com/latex.php?latex=S+%3D+%5Be_1%2Ce_2%2C+%5Ccdots+e_n%5D&bg=ffffff&fg=393939&s=0&c=20201002)
Now remove one item from the set:
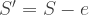
This new set 


The converse is not necessarily true, however. Just because you have an optimal set for some subproblem, adding any arbitrary element to your set does not make your new set optimal.
But adding an element to an optimal subset may create another optimal subset. This depends on which is smaller- the cost obtained by adding the element, and the cost obtained by not adding the element.
It’s probably better to express this idea recursively:

Here 
Obviously when 
The first path, 
The second path, 
The code doesn’t handle all the edge cases. For example if we only have one possible item to dump, we are forced to dump it until the weight is reached; we can’t just decide not to dump any more of it and end up with an empty list.
If we use this code, the program will start unfolding the recursion:

Being a recursive function, we can go further:

Now having reached the end of the recursion, we can fill up the tree from bottom up:

Whenever we reach a node that is the parent of the two nodes, we fill it up with the smaller of the two child nodes.
Now let’s transform this recursive function into a dynamic programming routine.
Instead of a function taking two parameters, we have the intermediate results stored in a two-dimensional array:

Here the first row is the optimal solutions for each weight using only A, while the second row is by using A and B.
Filling up the first row is very obvious, as we basically only have one item to choose from:

The first few cells of the second row is equally easy:

However we now reach a point where it’s uncertain what we should put in the cell with the question mark. If we follow our pattern, it should be 20.
But the cell above it is 14. How can the optimal solution when we’re allowed to use both A and B be 20, if the optimal solution when we’re not allowed to use B is 14?
Instead, the cell should be 14:

We continue this to fill up the entire array:

The bottom right corner of this array is our answer.
The computational complexity of this algorithm is the size of the array, or 
This is because as W‘s length increases, the running time increases exponentially. If, in our example, W was actually 13000000 instead of 13, and A weighed 5000000 instead of 5, and B weighed 3000000 instead of 3, this algorithm might run out of space.
There is no real way around this problem. The knapsack problem is NP-complete to solve exactly.
However there’s something we can do about it. We can divide all weights by a common factor, and the result would be the same. In the example we can simply divide 13000000, 5000000, and 3000000 all by a million.
Needless to say, this would fail badly if W had been, for instance, 13000001.
The implementation
With the algorithm, it’s pretty straightforward to implement it.
Here’s my implementation in Java (don’t cheat though):
import java.io.*;
import java.util.*;
public class usrbincrash{
public static void main(String[] args) throws Exception{
BufferedReader in = new BufferedReader(
new FileReader(args[0]));
// Minimum weight to prevent crash
int crashw = Integer.parseInt(in.readLine());
// List containing weights of items
List<Integer> itemW = new ArrayList<Integer>();
// List containing values of items
List<Integer> itemV = new ArrayList<Integer>();
String parse;
while( (parse = in.readLine()) != null){
Scanner scn = new Scanner(parse);
scn.next();
itemW.add(scn.nextInt());
itemV.add(scn.nextInt());
}
// Take the GCD's before starting the DP
int gcd = crashw;
for(int i : itemW) gcd = gcd(gcd, i);
// Divide all weights by gcd
crashw /= gcd;
for(int i=0; i<itemW.size(); i++)
itemW.set(i, itemW.get(i)/gcd);
// Calculate optimal fit using dynamic programming
int[][] dp = new int[itemW.size()][crashw+1];
// First row of DP array done separately
dp[0][0] = 0;
for(int j=1; j<=crashw; j++){
int aW = itemW.get(0);
int aV = itemV.get(0);
if(aW > j) dp[0][j] = aV;
else dp[0][j] = aV + dp[0][j-aW];
}
// Filling up the rest of the DP array
for(int i=1; i<dp.length; i++){
dp[i][0] = 0;
for(int j=1; j<=crashw; j++){
int iW = itemW.get(i);
int iV = itemV.get(i);
// Cell directly up from current
int imUp = dp[i-1][j];
// Cell left of it by iW
int imLeft = 0;
if(iW > j) imLeft = iV;
else imLeft = iV + dp[i][j-iW];
// Smallest of the two
dp[i][j] = imUp<imLeft? imUp: imLeft;
}
}
System.out.println(dp[itemW.size()-1][crashw]);
}
// GCD using the Euclid algorithm
static int gcd(int a, int b){
if(b == 0) return a;
return gcd(b, a%b);
}
}
When submitting it, it’s necessary to use the -Xmx1024m option. Otherwise the program will run out of memory and fail. According to the robot, the longest test case took 2911.623 ms to run.

You can greatly reduce the space you are using by keeping in mind that you only use 2 lines from dp matrix (current one and previous one).
LikeLike
Awesome Explanation. Great Work!!
LikeLike