
It’s been a while since I’ve written anything mathematical on this blog, but one of my courses this term was really neat: Coding Theory (CO331). I liked it because it lies in the intersection between pure math and computer science: it applies abstract algebra to the concrete problem of sending messages.
Coding theory deals with encoding a message so that even if some errors occur during transmission and a few digits get flipped, the original message can still be recovered. This is not the same as cryptography — we’re not trying to hide the message, only correct errors.
What is a code?
How would you encode a message (assume it’s in binary), so that if one bit is flipped, you can still recover the message?
Well, an obvious way is to send each letter 3 times, so 0110 becomes 000111111000. Then to decode, we take the majority in each block of 3 letters, so as long as each block has only one error, we will always decode correctly. This is a an example of a code, with the codewords being {000, 111}.

In general, a code is a set of strings (codewords) of the same length. We send a codeword through the channel, where a few bits get flipped. Then, the decoder corrects the received word to the closest word in the code (nearest neighbor decoding).
The distance of a code is the minimum number of bit flips to transform one codeword to a different one. In order for a code to be able to correct a lot of errors, the distance should be high. In fact, if the distance is 

We can visualize a code as a collection of spheres, centered around the codewords. Each sphere corresponds to the words that get corrected to the codeword in the middle.

A desirable code needs to have a high distance and a large number of codewords. This way, it can correct a lot of errors, without being too redundant. The rate of a code is

This represents the efficiency: how much we’re paying to achieve the desired error correcting capability. The triplication code in the example has 2 codewords, each of length 3, so the rate is 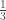
Also, in coding theory, we’re not really concerned with how to transform a plaintext message into a stream of codewords. Given a code consisting of a set of codewords and a procedure to correct a received word to the nearest codeword, the rest is “just an engineering problem”.
These definitions set the scene for what’s coming next. As I said before, a good code should have a high distance as well as a large number of codewords. It also needs to be efficient to decode — with general codes, there is no better way to decode than to check every codeword to find the closest one to your received word — clearly, this is no good. To do better, we need to construct codes with algebraic structure.
Linear Codes
A linear code is a code where a linear combination of codewords is another codeword.
This is useful because now we can apply a lot of linear algebra machinery. The set of codewords now form a vector space, and from linear algebra, every vector space is spanned by a set of basis vectors. Then, to specify a code, we can write the basis vectors as rows of a matrix — this is called a generator matrix of a code.
Let’s do a concrete example. Consider a code where each word is 5 digits (each between 0-9), where the 5th digit is a “checksum” of the previous 4 digits modulo 10. For example, 98524 is valid because 9+8+5+2=24. This code cannot correct any mistakes, but can detect if a single typo has been made.
A generator matrix for this code is:
![G = \left[\begin{array}{ccccc}1&0&0&0&1\\ 0&1&0&0&1 \\ 0&0&1&0&1 \\ 0&0&0&1&1 \end{array}\right]](https://s0.wp.com/latex.php?latex=G+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D1%260%260%260%261%5C%5C+0%261%260%260%261+%5C%5C+0%260%261%260%261+%5C%5C+0%260%260%261%261+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=393939&s=2&c=20201002)
If we add up any linear combination 
![x = [9,8,5,2]](https://s0.wp.com/latex.php?latex=x+%3D+%5B9%2C8%2C5%2C2%5D&bg=ffffff&fg=393939&s=0&c=20201002)
![x G = [9,8,5,2,4]](https://s0.wp.com/latex.php?latex=x+G+%3D+%5B9%2C8%2C5%2C2%2C4%5D&bg=ffffff&fg=393939&s=0&c=20201002)
For any linear code, we can find a parity-check matrix H, which lets us quickly check if a word is in the code or not: given a word 

![H = \left[ \begin{array}{cccccc} 1&1&1&1&-1 \end{array} \right]](https://s0.wp.com/latex.php?latex=H+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccccc%7D+1%261%261%261%26-1+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=393939&s=2&c=20201002)
Using the parity-check matrix, we can easily detect errors, but correcting to the nearest codeword is still NP-hard for general linear codes. However, certain classes of linear codes have tractable decoding algorithms:
- Hamming Codes: class of single-error correcting codes with distance 3.
- Binary Golay Code: block length 24 and distance 8, so it can correct 3 errors.
Cyclic Codes
A cyclic code is a linear code where a rotation of any codeword is another codeword. (Since all cyclic codes are linear codes, any linear combination of codewords is still a codeword).
Cyclic codes are closely connected to polynomials, and we can write a codeword as coefficients of a polynomial: for example, 703001 is 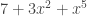


Furthermore,
where
is the block length. For algebraic reasons that are difficult to explain, this ensures that
, and we can always get rid of higher powers by replacing them with lower power terms.
For example, consider a binary cyclic code of block length 3, with generator polynomial 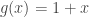
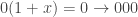

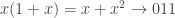

The codewords are {000, 110, 011, 101}. A rotation of a word to the right is the same as multiplying the corresponding polynomial by 
Cyclic codes are very good at correcting burst errors, where errors are assumed to occur consecutively, instead of distributed evenly across the entire word. However, cyclic codes do not always have high distance. Some special classes of cyclic codes do have high distance, and are more suitable for general error correction:
- BCH Codes: cyclic codes constructed to have high distance. They can be decoded efficiently, but the algorithm is a bit complicated.
- Reed-Solomon Codes: special class of BCH codes suitable for use in practice. These are widely used for error correction in CDs, DVDs, and QR codes.

Nicely summarized.
LikeLike