
A while ago, I wrote a minesweeper AI. I intended to publish a writeup, but due to university and life and exams, I never got around to writing it. But having just finished my Fall term, I have some time to write a decent overview of what I did.
Short 30 second video of the AI in action here:
How to Play Minesweeper
If you’re an experienced minesweeper player, you can probably skip this section. Otherwise, I’ll just give a quick overview of some basic strategies that we can use to solve an easy minesweeper game.
We start with a 10×10 Beginner’s grid, and click on a square in the middle:

We can quickly identify some of the mines. When the number 1 has exactly one empty square around it, then we know there’s a mine there.
Let’s go ahead and mark the mines:

Now the next strategy: if a 1 has a mine around it, then we know that all the other squares around the 1 cannot be mines.
So let’s go ahead and click on the squares that we know are not mines:

Keep doing this. In this case, it turns out that these two simple strategies are enough to solve the Beginner’s grid:

Roadmap to an AI
All this seems easy enough. Here’s what we’ll need to do:
- Read the board. If we use a screenshot function, we can get a bitmap of all the pixels on the board. We just need to ‘read’ the numbers on the screen. Luckily for us, the numbers tend to have different colors: 1 is blue, 2 is green, 3 is red, and so on.
- Compute. Run the calculations, figure out where the mines are. Enough said.
- Click the board. This step is easy. In Java, we can use the Robot class in the standard library to send mouse clicks to the screen.
Reading the Field
There’s not a whole lot to this step, so I’m going to skim over it quickly.
At the beginning of the run, while we have a completely empty grid, we invoke a calibration routine – which takes a screenshot and looks for something that looks like a Minesweeper grid. Using heuristics, it determines the location of the grid, the size of a grid square, the dimensions of the board, and things like that.
Now that we know where the squares are, if we want to read a square, we crop a small section of the screenshot and pass it to a detection routine, which looks at a few pixels and figures out what’s in the square.
A few complications came up in the detection routine:
- The color for the number 1 is very close to the color of an unopened square: both are a dark-blue color. To separate them apart, I compared the ‘variance’ of the patch from the average color for the patch.
- The color for 3 is identical to that for 7. Here, I used a simple edge-detection heuristic.
Straightforward Algorithm
The trivially straightforward algorithm is actually good enough to solve the beginner and intermediate versions of the game a good percent of the time. Occasionally, if we’re lucky, it even manages to solve an advanced grid!
When humans play minesweeper, we compete for the fastest possible time to solve a grid of minesweeper. So it doesn’t matter if we lose 20 games for every game we win: only the wins count.
This is clearly a silly metric when we’re a robot that can click as fast as we want to. Instead, we’ll challenge ourselves with a more interesting metric:
Win as many games as possible.
Consider the following scenario:

Using the straightforward method, we seem to be stuck.
Up until now, whenever we mark a square as having a mine or safe, we’ve only had to look at a single 3×3 chunk at a time. This strategy fails us here: the trick is to employ a multisquare algorithm – look at multiple different squares at once.
From the lower 2, we know that one of the two circled squares has a mine, while the other doesn’t. We just don’t know which one has the mine:

Although this doesn’t tell us anything right now, we can combine this information with the next 2: we can deduce that the two yellowed squares are empty:

Let’s click them to be sure.

And voilà. They’re empty. The rest of the puzzle can be solved easily, after we’ve made the deduction that those two squares were empty.
The Tank Solver Algorithm
It’s difficult to make the computer think deductively like we just did. But there is a way to achieve the same results, without deductive thinking.
The idea for the Tank algorithm is to enumerate all possible configurations of mines for a position, and see what’s in common between these configurations.
In the example, there are two possible configurations:

You can check for yourself that no other configuration could work here. We’ve deduced that the one square with a cross must contain a mine, and the three squares shaded white below must not contain a mine:

This works even better than human deduction!
We always try to apply the simple algorithm first, and only if that gets us stuck, then we bring in the Tank algorithm.
To implement the Tank algorithm, we first make a list of border tiles: all the tiles we aren’t sure about but have some partial information.
Now we have a list of 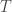
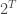
The optimization is segregating the border tiles into several disjoint regions:

If you look carefully, whatever happens in the green area has no effect on what happens in the pink area – we can effectively consider them separately.
How much of a speedup do we get? In this case, the green region has 10 tiles, the pink has 7. Taken together, we need to search through 
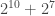
Practically, the optimization brought the algorithm from stopping for several seconds (sometimes minutes) to think, to giving the solution instantly.
Probability: Making the Best Guess
Are we done now? Can our AI dutifully solve any minesweeper grid we throw at it, with 100% accuracy?
Unsurprisingly, no:

One of the two squares has a mine. It could be in either, with equal probability. No matter how cleverly we program our AI, we can’t do better than a 50-50 guess. Sorry.
The Tank solver fails here, no surprise. Under exactly what circumstances does the Tank algorithm fail?
If it failed, it means that for every border tile, there exists some configuration that this tile has a mine, and some configuration that this tile is empty. Otherwise the Tank solver would have ‘solved’ this particular tile.
In other words, if it failed, we are forced to guess. But before we put in a random guess, we can do some more analysis, just to make sure that we’re making the best guess we could make.
Try this. What do we do here:

From the 3 in the middle, we know that three of them are mines, as marked. But marking mines doesn’t give us any new information about the grid: in order to gain information, we have to uncover some square. Out of the 13 possible squares to uncover, it’s not at all clear which one is the best.
The Tank solver finds 11 possible configurations. Here they are:

Each of these 11 configurations should be equally likely to be the actual position – so we can assign each square a probability that it contains a mine, by counting how many (of the 11) configurations does it contain a mine:

Our best guess would be to click on any of the squares marked ‘2’: in all these cases, we stand an 82% chance of being correct!
Two Endgame Tactics
Up until now, we haven’t utilized this guy:

The mine counter. Normally, this information isn’t of too much use for us, but in many endgame cases it saves us from guessing.
For example:

Here, we would have a 50-50 guess, where two possibilities are equally likely.
But what if the mine counter reads 1? The 2-mine configuration is eliminated, leaving just one possibility left. We can safely open the three tiles on the perimeter.
Now on to our final tactic.
So far we have assumed that we only have information on a tile if there’s a number next to it. For the most part, that’s true. If you pick a tile in some distant unexplored corner, who knows if there’s a mine there?
Exceptions can arise in the endgame:

The mine counter reads 2. Each of the two circled regions gives us a 50-50 chance – and the Tank algorithm stops here.
Of course, the middle square is safe!
To modify the algorithm to solve these cases, when there aren’t that many tiles left, do the recursion on all the remaining tiles, not just the border tiles.
The two tricks here have the shared property that they rely on the mine counter. Reading the mine counter, however, is a non-trivial task that I won’t attempt; instead, the program is coded in with the total number of mines in the grid, and keeps track of the mines left internally.
Conclusion, Results, and Source Code
At this point, I’m convinced that there isn’t much more we could do to improve the win rate. The algorithm uses every last piece of information available, and only fails when it’s provably certain that guessing is needed.
How well does it work? We’ll use the success rate for the advanced grid as a benchmark.
- The naïve algorithm could not solve it, unless we get very lucky.
- Tank Solver with probabilistic guessing solves it about 20% of the time.
- Adding the two endgame tricks bumps it up to a 50% success rate.
Here’s proof:

I’m done for now; the source code for the project is available on Github if anyone is inclined to look at it / tinker with it:
https://github.com/luckytoilet/MSolver
Further discussion on Reddit and in the comments below!

What version of Minesweeper is that? Windows 7?
Have you tried finding a version of Minesweeper online (say, in Flash or HTML5) and porting your AI to that version so that people can experiment with it outside of Windows? Alternatively, do any commenters feel like *writing* a Flash or HTML5 Minesweeper clone?
LikeLike
Holy cow, dude, just get a copy of Windows.
LikeLike
To be honest, it should be fairly trivial to write a minesweeper clone – I can’t imagine anything in it being particularly complicated. I would do it myself, but I’ve currently got enough things on the go.
LikeLike
Hey, what’s you talking about?
$ apt-cache search minesw
freesweep – text-based minesweeper
gnomine – popular minesweeper puzzle game for GNOME
kmines – minesweeper game
sgt-puzzles – Simon Tatham’s Portable Puzzle Collection – 1-player puzzle games
xbomb – ‘minesweeper’ game with squares, hexagons or triangles
xdemineur – Yet another minesweeper for X
LikeLike
Not everyone uses a Debian based Linux system, but he might be able to search for the sources to a few of those.
LikeLike
And not everybody deserves to get whatever program he wants for his obscure whatever OS.
If he is not using Windows, a popular Linux distro, OS X or FreeBSD, then he should go and find the game himself.
And it’s not like parent comment meant just “here are apt-get binaries of the game”. It was more in the spirit of “hey, dude, tons of bloody OSS implementations exist”.
LikeLike
I’m aware of freeware Minesweeper clones. However, I wouldn’t necessarily assume that the OP’s code will “just work” when presented with those UIs. And if the OP switched to using something like gnomine, then he’d be shutting out the readers who use *Windows*.
Hence, my suggestion that the OP (a) clarify which version[s] of the Minesweeper UI he was using, and (b) consider switching to a more portable UI, such as one written in Flash or HTML5.
I think a lot of the commenters here haven’t realized that the OP’s code works by screen-scraping a specific UI, as opposed to… um… magic? 😛
LikeLike
This entire comment is erroneous and irrelevant. The OP is writing an article on the theory and process behind building a Minesweeper AI, and is *clearly* providing the source code as an example of how the algorithms and theory explained could be implemented in code.
At no point is he “shutting out” any readers, or did he claim that it would “just work” for anybody. The service he is providing is not writing a program that you can use, but teach you the process behind making an AI for minesweeper.
If you want to use a minesweeper AI, and not use the minesweeper client for which the OP’s code is *written for*, then stop asking someone to do it for you and WRITE YOUR OWN.
LikeLike
Here ya go: http://benru.nl/mines.html All open source, written in javascript and html.
I wrote that like 6 years ago, so the code is horrible and it’s not tested on all browsers (but it does work on the newest Opera). It does the trick though and looks exactly like the xp minesweeper. You can alter the graphics yourself by just changing the gifs.
LikeLike
Could you speed it up by not marking flags on the squares? I always play without using flags. The last click on the last empty box will auto-place flags on all mines and win the game.
LikeLike
If you middle click on a number that already has the correct amount of marked bombs around it, it will open the rest of the squares touching that number. This is just about the only way to get a reasonable time.
Pointless when you’re writing an AI though.
LikeLike
that’s not ai, that’s just an algorithm. you lied to me
LikeLiked by 1 person
ai IS just an algorithm …
LikeLike
Er, AI is all about algorithms.
And especially “Game AI” refers to exactly this kind of algorithms.
What did you expect? Thinking robots?
LikeLike
Are you a robot?
LikeLike
I have done much the same thing. However for the first move I always choose a corner square. It’s just as likely to contain a bomb as any other square, but as it only has 3 neighbors there is more chance of it not being adjacent to a bomb. So then the board opens up a little (or sometimes a lot).
LikeLike
Also, your 11 possible configurations leads to the wrong probabilities. The right column which reads 2,7,2 is completely wrong. Without using the total number of bombs left, those three squares each have a 1 in 3 chance of containing a bomb.
LikeLike
Your 11 possible configurations range from 7 to 9 flags. This by itself shows that you can’t just add up the flags and expect it to produce the correct odds.
LikeLike
Of the 11 combinations, two have 7 flags, three have 9 flags and six have 6 flags. If you know how many bombs are going to fit into these 16 ‘border’ squares, then by all means assign each combination an equal probability. But if you don’t know then you can’t do it that way.
LikeLike
Sorry, I meant that six have 8 flags. So over half the solutions have 8 flags, but your logic assumes that 7 flags is just as likely as 8. This is where I disagree – you can’t know that.
LikeLike
Actually you are giving more weight to solutions with 8 flags than to those with 7 or 9.
LikeLike
If we assign a probability of a bomb to each of the vacant squares (starting from top left and moving counter-clockwise), I would use these percentages (rounded):
67, 67, 67, 67, 40, 40, 33, 33, 20, 33, 33, 33, 33.
Which suggests there is a single best move. And none of your 6 best moves have an 82% success rate. I find one square with an 80% chance.
LikeLike
Sheesh, 1kSLC+ in a single .java file 😦
LikeLike
@Bomb:
You’re right that not all 11 possibilities have the same probability of occurring — in order to give completely correct probabilities we do need to take into account the number of mines left. We do this in the second endgame tactic stage, because it’s more computationally feasible then.
I’m not sure how you got your probabilities. In the post, I never told you how many mines were left on the board, so I’m not sure how you could do a more accurate calculation without this information. (I think I set it to 200 mines to take the screenshot)
Also, on Windows 7 minesweeper, the first click always opens up its surrounding 3×3, while on XP you’re only guaranteed the one square been open.
LikeLike
It’s amazing how much work you put into this. Yes, the amount of mines left and the amount of mines adjacent to numbers do affect the probability of each combination. Now all combination are equally likely to happen.
Specifically, there are 13 squares adjacent to mines (this excludes the 3 squares on the top wall that are already proven to be mines) and the amount of mines in them range from 4 to 6 (again, excluding the top 3 mines). Let’s call the number ranging from 4 to 6 as “x”. Let’s define the amount of squares nonadjacent to numbers as “n”. We also don’t know the amount of remaining mines, so let’s call that “m”.
So, we must find all possible combinations of the “m-x” mines nonadjacent to the numbers, within the “n” squares nonadjacent to the numbers.
I personally use a Pascal’s triangle calculator and find the “m-x”th number in the “n”th row of the triangle (of course, including the 0th number and 0th row).
Once you get all 3 pascal numbers for all 3 possible numbers of x (4, 5, and 6), you have the probability of each combination depending on your x, the number of mines in the squares adjacent to the numbers.
P.S. Of course, this is assuming the numbers you’ve displayed were the only numbers that were on the board. If not, shit gets fucking ridiculously complicated. *shudder* I wouldn’t want to even think of that. I tried before. I’ve seen true terror.
LikeLike
How exactly did you determine the environment from screen shot. For example the grid size and so on. Was it simple as if screenSize.width == knownWidthForEasyVersion then create array with easy version size and so on?
LikeLike
No, there’s some crude computer imaging. It takes a screenshot and looks for ‘crosses’ at right angles (ie, the crosses formed by lines separating squares). Once it’s found the crosses, it works backward to deduce the size and position of the grid.
LikeLike
Nice at least Im not the only one to do this. I did it way back in 1995ish when I got annoyed with a crappy mouse. My version worked on win3.11 win 95 win 98, and NT. sadly it doesn’t work on vista or win 7. The biggest problem with it is now that my AI can win beginner in under 1 second and expert in under 10 seconds I never play it anymore…. 😦
LikeLike
Pingback: How to write your own Minesweeper solver
Pingback: How to write your own Minesweeper solver | Daily IT News on it news..it news..
How fast are the best times?
LikeLike
Pingback: – How to write your own Minesweeper solver
Great algorithm, thanks for sharing this.
LikeLike
Reblogged this on Of_Drifter.
LikeLike
Heh, I did the exact same thing 12 years ago. Note that the probabilities are perfectly computable across the entire grid, so you can consider a probabilistic solver to be “perfect” even though it may not be right all the time.
LikeLike
I noticed your Straightforward Algorithm is basically a constraint satisfaction problem. I had to make a minesweeper AI as well and discovered that winning expert was achievable to ~33.33%
LikeLike
Reblogged this on Andrew Rauh.
LikeLike
Pingback: AI to solve minesweeper
Congratulations!
I did the same about 15 years ago (I was young, and in Army, and very bored), complete with graphic-detection routine and the optimal calculations.
The result was terrific and fun – for about 1 day.
I beat everybody’s scores. More specifically, the program did. I was very proud.
I had to update the graphic detection routine when the next Windows version came out. I did not bother with the one after that.
That is not “AI”, though. There is no “self” intelligence in the program; it only makes the calculations that you have programmed into it.
It looks very intelligent to the outsiders … but that’s not what we call “real intelligence” 🙂 🙂
LikeLike
Pingback: Languages, Games & Daisy « Kynosarges
Pingback: Solving Minesweeper with Matricies « Programming by Robert Massaioli
Pingback: A Minesweeper sover with AI | Hacking Software Engineering
Can anyone tell me, where can I get original WinXP minesweeper? I am playing minesweeper at http://jscr.co/minesweeper/ because it resembles a lot an old one.
LikeLiked by 1 person
Pingback: Inteligencia artificial para resolver el “Buscaminas” | unocero.com
Pingback: Inteligencia artificial para resolver el “Buscaminas” « Caricarisoft
I love the Probability section and it has been something I’ve been looking into for awhile now. But there’s another factor to truly making the best guess, and that is to pick the square that will give the most information. Or, hell, picking the square that is MOST LIKELY to give the most information.
To do this, two steps: the first step is to see what else would be found out for sure if you guessed a square and got it right. Second step is to figure all possible numbers that will appear on the square you picked and what probability each number will appear, and then finding what other squares can be found for sure with each resulting number.
In your Best Guess example, if you were to pick the “2” square on the middle of the right wall (oh god, I’m sorry. I really should have illustrations for this.), then you might get a 1, 2, 3, or 4. Obviously 2 or 3 is more likely, and either is more likely than the other depending on the mine density of the board. If you get 2, 3, or 4, you’re screwed and you have to make another guess. The same can be said for the “2” square on the middle of the bottom wall.
On the other hand, if you pick the “2” square on the lower part of the right wall, or the “2” on the bottom left corner (again, I’m sorry I don’t have illustrations), then you are sure to get some more information, and you’re more likely to get lucky with the numbers you might get. I don’t know if the lower square of the right wall or the bottom left corner square is the better guess, but they’re so clearly better than the other two “2” guesses.
LikeLike
Pingback: Tatham Puzzle Collection: problem solving strategies
Pingback: Solving Minesweeper with Matrices | Programming by Robert Massaioli
Pingback: Minesweeper AI Plan | Stefan Larsen
Pingback: Minesweeper AI – Coordinated Coding
Pingback: Minesweeper AI – Implementation | gauzewave
Pingback: Code Report: A Parallel Solution to Minesweeper AI | johnparsaiegraphics
Pingback: Minesweeper AI Solver (Planning) – Brandon Cote
Pingback: Minesweeper AI: Planning – Morgen Hooley Programming Blog
Pingback: Planning Minesweeps – Aaron Millet – Artificial Opponents
Pingback: Minesweeper AI Planning Stage – Spiker Games
Pingback: Minesweeper AI: Code Report – Morgen Hooley Programming Blog
Pingback: Minesweeper AI Code Report | Spiker Games
Wow! amazing job. maybe I will implement it to work on this online minesweeper: http://minesweeper.mineblown.com
LikeLike
I have written my own MineSweeper solver coming from a different direction. My version creates its own puzzles and then tries to solve them. I have made some refinements to the algorithm above and created a second method when guessing is required that uses all entries not on the sequences (segregating as he calls it). In addition I have answered questions like where is the best place to start (I was surprised) and of course what the actual winning percentage is (the number of puzzles solved above are too low to have much confidence in their numbers). I will make the source code available when I am done refining it. It is written in C for Visual Studio.
To summarize I ran 6 1000 sample runs and here are the winning percentages:
46.8%, 44.5%, 46.3%, 48.7%, 45.9% and 47.5% for an average of 46.62%
LikeLike
Cool — so it seems that I got slightly lucky with my 50% winrate!
LikeLike
The default value for number of remaining open entries to use end play (15) was chosen using this data.
These all use (3,3) as the starting position. All tests use 100 sample puzzles. As you can see it makes little difference.
endPlay 6 8 10 12 13 14 15 16 17 18 20 22 24
seed ————————————————————————————–
123 47 47 47 47 47 47 47 47 47 47 47 47 46
234 44 44 45 45 45 46 46 46 46 46 48 47 48
345 47 47 48 48 48 49 49 49 49 49 48 49 49
456 52 52 52 52 52 52 53 52 52 52 51 51 51
1234 37 37 37 37 38 38 38 38 38 38 38 37 36
———————————————————————————————-
Totals 227 227 229 229 230 232 233 232 232 232 232 231 230
LikeLike
As I mentioned earlier there are some refinements that can be made to the algorithm first mentioned by the author above. First when you segregate border tiles (I call this creating a sequence of linked tiles) and proceed to create solutions for each sequence, limit the number of mines allowed to the current mine count minus the number of sequences plus 1. Of course when in end play you will have one sequence so you will limit your max as well as min mine count to the actual mine count.
Now for the second more interesting part. If the sum of the max mines used for all sequences exceeds the mine count you can go back and recheck the possible solutions reducing the max limit. For example suppose we find three sequences with min and max mine counts of (2,2), (11,13), and (2,2) but only 15 mines left. So we recheck solutions for the second sequence limiting it to 11 mines. Or suppose you find four sequences with min and max mine counts of: (1,1), (4,6), (6,8), and (1,1) but only 13 mines remaining. This means that we cannot have the second sequence use 6 mines nor have the third sequence use 8 mines. So now we can go back and retest these two sequences using a max of 5 and 7 respectively.
A third optimization occurs when we have situations where the sequences take up all the remaining unexposed entries in the puzzle and yet end play is not yet invoked and there is more than one sequence and min != max. For example, we have two sequences with min and max mine counts of (5,6) and (2,3) with 8 mines remaining. The first sequence has 4 solutions and the second 3 solutions and there is no obvious choice where to play. However if we combine the two sequences into one and invoke end play we find there are 8 solutions but one location has 0% chance of a mine!
This leads to the obvious rule that is not mentioned above. After using the tank method, if you have any entry with 100% chance of a mine or 0% chance of a mine, then make the obvious choice.
However, if you have equal choices between two or more locations there are reasons to pick one over another. In the author’s example above where there are several places with a count of two, I can see two places where I would play over the others. Any time you have three tiles in a row or column it is often better to play in the middle adjacent to them so that if a one is exposed then we can make some obvious selection to expose as many as three other tiles. However, if you picked the diagonal positions there are few values that will help. So my fourth optimization I have an evaluation method which I will not go into here but it does pick these more likely spots.
One optimization I have not done is to expose a mine where it is more likely than exposing a non-mine entry. Nor have I done any look ahead (if I place a mine here will that help make an obvious choice). I will look into those later.
I also have a second method for guessing that does not use the tank method and I will describe at some point in the future.
I forgot to mention that the original 6000 sample runs use some starting parameters that may not be optimal (start=3,3 endplay=14, offset=-.03). I will explain these numbers later.
I am working on this program and I find bugs or improvements every day I work on this. When I get done I will post better numbers. As for now I am trying to find out why some starting positions have better results than others.
LikeLike
As I mentioned there is another type of guess that can be used. I call this version guess1 and the original version above I call guess2. In any case when you create the linked sequences of entries required by the tank method, keep a min and max number of mines used for each sequence. Now any remaining unexposed entries minus any entries in the sequence list can be used to create a new list which I call the free list. Estimate the number of mines in this free area by taking the sum of (min + max) / 2 mines for each sequence. Now the odds of getting a mine in the free area is the number of free entries divided by the estimate of mines. Now if these odds are lower that the best guess using the tank method you may want to use guess1 instead.
If you do use guess1 there are two different ways you can go. You can pick an entry next to a sequences to help support any sequence. This the first choice because you are likely to get some help that will hep solve more of the puzzle. I look for situations that look like this:
XXX
– – –
?
I will pick the ? entry even if one of the X positions are off the edge. Actually my method is a little more complicated that this but I will skip the details. If I cannot find one these situations I will try to find a free entry with the fewest number of free entries around it. The goal is to expose an area with no mines around it. This is almost always a corner but if they are taken an edge will do too. I will not fill an entry surrounded by mines unless there is 100% chance it is not a mine.
Because the odds for guess1 are just an estimate I added an offset to the odds to try to optimize the best time to use it. I call this my guess1 off and after running 12,000 samples the results are shown in following table. So I have decided to use -3%. This means if the odds of a mine in the free area minus 3% is less than the odds using guess2, then we use guess1.
Average Percent Std. Dev.
———————————–
-0.06 46.50% .42%
-0.05 46.70% .43%
-0.04 46.70% .43%
-0.03 46.77% .43%
-0.02 46.57% .43%
Next I will provide information on the best value of “end play” which is the number of remaining entries before we invoke the end play method.
BTW the 50% quoted by the author has a standard deviation of 6.2% for the 67 samples he used. So yes he got lucky.
LikeLike
The default value for end play (30) was chosen using the data below. As one would expect the results get better with the high end play values. I stopped at 30 because of CPU constraints. It will take longer
to calculate all solutions with unconnected sequences of length greater than this.
Here is some sample results using 10 different random seeds and 4000 samples:
endPlay Wins Percent Std. Dev.
————————————————————————————————————–
6 1825 45.6% 0.72%
8 1831 45.8% 0.72%
10 1847 46.2% 0.73%
12 1851 46.3% 0.73%
13 1852 46.3% 0.73%
14 1856 46.4% 0.73%
15 1857 46.4% 0.73%
16 1858 46.5% 0.73%
17 1858 46.5% 0.73%
18 1859 46.5% 0.73%
19 1859 46.5% 0.73%
20 1858 46.5% 0.73%
21 1858 46.5% 0.73%
22 1861 46.5% 0.74%
23 1862 46.6% 0.74%
24 1858 46.5% 0.73%
25 1861 46.5% 0.74%
26 1862 46.6% 0.74%
27 1866 46.7% 0.74%
28 1870 46.8% 0.74%
29 1874 46.9% 0.74%
30 1874 46.9% 0.74%
Next I will post the results of my starting position analysis.
LikeLike
Here are the results using end play = 30 and guess1 offset = -3%. These runs use 30 random seeds
of 500 puzzles. As I mentioned in my early post there are some strange numbers here which I do not understand. If anyone has any idea why, please let me know. As best as I can tell starting at 3,2 is better than anything else in the upper left quadrant. There are some other good choices marked.
Pos Set1 Set2 Set3 Totals Percent Std. Dev.
————————————————————————————————————–
0,0 1938 1990 1928 5856 39.04% .32%
1,1 2154 2207 2233 6594 43.96% .36%
2,2 2276 2353 2359 6988 46.59% .38% good
2,1 2243 2311 2274 6828 45.52% .37%
1,2 2226 2277 2309 6812 45.41% .37%
3,3 2279 2350 2373 7002 46.68% .38% good
3,2 2341 2369 2383 7093 47.29% .39% best
2,3 2322 2321 2351 6994 46.63% .38% good
3,1 2184 2278 2251 6713 44.74% .37%
1,3 2283 2329 2270 6882 45.88% .37%
4,4 2161 2313 2296 6770 45.13% .37%
4,3 2204 2333 2369 6906 46.04% .38%
3,4 2261 2302 2360 6923 46.15% .38%
4,2 2178 2358 2300 6836 45.57% .37%
2,4 2284 2247 2337 6868 45.79% .37%
4,1 2174 2283 2271 6728 44.85% .37%
1,4 2176 2275 2287 6738 44.92% .37%
0,7 2191 2236 2232 6659 44.39% .36%
1,7 2241 2284 2287 6812 45.41% .37%
2,7 2312 2334 2352 6998 46.65% .38% good
3,7 2297 2318 2322 6937 46.25% .38%
4,7 2259 2301 2300 6860 45.73% .37%
LikeLike
Most of the stats below are self explanatory, however, there are a few that
need explanations or is of some interest.
* Guess1 failed is less than Guess2 failed is always a good sign because it
means we are doing the right thing picking Guess1 first.
* Average Guess1 probability is higher than Guess2 also means we are making
the right choice to use Guess1 instead of Guess2. Notice the high probability
of success for both Guess1 and Guess2. This is good.
* The average number of guesses per win is close to two means we generally
need to guess twice before winning.
* The average number of guesses per loss is often close to one more than
a win which is what I would expect.
* Notice we can win less 16% of games without guessing and only another 10%
guessing only once. In general we win 33% of games guessing twice or less.
* The average win/loss probability is the product of all guesses so far up
until we win or lose.
So putting this all together using start=3,2, endPlay=15, guess1Offset=-.03 we get
the following using results using 10,000 puzzles:
Wins 4696
Percent 46.96% deviation = .47%
Guess1 used = 9395
Guess2 used = 14159
Guess 1 failed=17.7%
Guess 2 failed=25.0%
Average guesses per win= 1.806
Average guesses per loss= 2.804
Average Loss Prob= 56.9%
Average Win Prob= 71.67%
Average Loss Prob= 56.48%
Average Guess 1 Prob= 85.13%
Average Guess 2 Prob= 76.65%
Wins with guesses
0 1 2 3 4 5 6 7 8+
1633 1025 707 490 312 191 119 87 132
LikeLike
Running the same 5000 puzzles but without Guess1 produces the following results:
Start Win w/o Guess1
———————
0,0 38.6% 33.4%
1,1 44.7% 41.0%
2,2 47.2% 45.3%
2,1 45.5% 43.1%
1,2 46.2% 43.6%
3,3 47.5% 45.8%
3,2 47.7% 45.5%
2,3 47.0% 45.1%
3,1 45.0% 43.4%
1,3 45.4% 43.7%
4,4 45.9% 44.7%
4,3 47.4% 45.8%
3,4 47.2% 45.2%
4,2 46.0% 44.7%
2,4 46.7% 45.6%
4,1 45.4% 43.6%
1,4 45.7% 44.0%
0,7 44.6% 41.6%
1,7 45.7% 44.3%
2,7 47.0% 45.2%
3,7 46.4% 45.1%
4,7 46.0% 44.2%
As you can see Guess1 helps a few percent.
LikeLike
Interesting experiments — have you considered writing your own blog post with these results? Comments on this post here will probably not get much attention.
LikeLike
This is my first time commenting on anything but I will look into it.
LikeLike
I thought about commenting on all the Reddit or https://puzzling.stackexchange.com or other web pages which have comments that seem so far off target. Do you have any other suggestions on where I should post my results? I do plan to put the source code on Github when I feel like it is a little more cleaned up.
LikeLike
I would write it up as best as I can in a blog post, and submitting it to Reddit (perhaps /r/programming). Not many people look at the comment sections of blog posts.
LikeLike
I started a new post at Reddit at:
LikeLike
For medium and small sized puzzles, here are some results:
Testing medium puzzles gives us the following results with each set being
5000 puzzles using 10 seeds each (and endPlay=30, Guess1Offset=-0.03):
Pos Set1 Set2 Totals Percent Std. Dev.
————————————————————————————————————–
1,1 4358 4297 8655 86.55% 0.87%
2,2 4413 4359 8772 87.72% 0.88%
2,1 4376 4352 8728 87.28% 0.87%
1,2 4369 4339 8708 87.08% 0.87%
3,3 4400 4330 8730 87.30% 0.87%
3,2 4432 4337 8769 87.69% 0.88%
2,3 4393 4345 8738 87.38% 0.87%
4,4 4384 4313 8697 86.97% 0.87%
Using start=3,2, endPlay=30, guess1Offset=-.03 we get the following
using 1000 samples:
Percent 87.6% deviation = 2.77%
Guess1 used= 100
Guess2 used= 309
Guess 1 failed=17.0%
Guess 2 failed=34.6%
Average guesses per win=0.26
Average guesses per loss=1.43
Average Win Prob= 94.0%
Average Loss Prob= 59.0%
Average Guess 1 Prob= 89.7%
Average Guess 2 Prob= 67.5%
Wins with guesses
0 1 2 3 4 5 6 7 8+
730 99 30 6 6 1 3 0 1
Testing SMALL puzzles gives us the following results with each set being
5000 puzzles using 10 seeds each (and endPlay=30, Guess1Offset=-0.03):
Pos Set1 Set2 Totals Percent Std. Dev.
————————————————————————————————————–
1,1 4816 4817 96.33 96.33% 0.96%
2,2 4844 4858 9702 97.02% 0.97%
2,1 4836 4835 9671 96.71% 0.97%
1,2 4846 4843 9689 96.89% 0.97%
3,3 4849 4840 9689 96.89% 0.97%
3,2 4840 4849 9689 96.89% 0.97%
2,3 4812 4823 9635 96.35% 0.96%
4,4 4813 4813 9626 96.26% 0.96%
Using start=3,2, endPlay=30, guess1Offset=-.03 we get the following
using 1000 samples:
Percent 96.7% deviation = 3.06%
Guess1 used= 35
Guess2 used= 73
Guess 1 failed=5.7%
Guess 2 failed=42.5%
Average guesses per win=0.07
Average guesses per loss=1.21
Average Win Prob= 98.4%
Average Loss Prob= 50.8%
Average Guess 1 Prob= 95.6%
Average Guess 2 Prob= 57.3%
Wins with guesses
0 1 2 3 4 5 6 7 8+
909 48 10 0 0 0 0 0 0
LikeLike
Online minesweeper to try out the algo: https://www.chiark.greenend.org.uk/~sgtatham/puzzles/js/mines.html
I was thinking of writing a solver myself – and started down the same path, of deductive thinking. I didn’t get to code, but tried what I thought out manually on a few expert boards. And then I found this: https://massaioli.wordpress.com/2013/01/12/solving-minesweeper-with-matricies/ IMO, it sort of models deductive thinking in a better way than using rules as a human would like them. In each step, you just have to write equations for all already uncovered squares. Fortunately, solving sytems of at best thousands of linear equations is an extremely light task for modern computers. You can, of course, optimize by always running a simple, straightforward step of marking all squares which _have to_ be mines and which are certainly without mines after each solving of the linear system.
LikeLike
I also saw this site but some sequences are quite large (in excess of 50 entries) so I did not want to solve matrices that large. Besides the algorithm mentioned above is much easier to optimize as I have mentioned.
I have updated my code to use a 64 bit pseudo random number generator (KISS) and sped up the program. I can give you a more updated numbers but for the expert game using 60,000 sample puzzles using 600 random seeds:
Pos Wins Percent est. Dev.
——————————————
3,3 28297 47.16% .21%
3,2 28172 46.95% .20%
2,3 28218 47.03% .20%
4,3 28030 46.72% .20%
3,4 28011 46.69% .20%
So there is really three best starting places in the upper left quadrant. So my original issue of why 3,2 was better than 2,3 was really a case of small test samples.
LikeLike
I have posted the source code to GitHub:
https://github.com/EdLogg/MineSweeper
LikeLike
I want to give you an update. The latest information can be found at the link below. To make a long story short, instead of estimating the probability when I have tank lists (perimeter area) with different number of mines, I now calculate the exact probability. In addition I can calculate the exact probability of the non-perimeter area too so I no longer need the guess1 offset. This results in a large increase in the chance of winning. For example, the expert game improves to more than 52%. Plus it was pointed out when I do guess I should consider reducing the solution space to reduce guesses. Also it appears my guess1 need only worry about guessing adjacent to the perimeter. This helps another half percent. Plus I am now in the process of implementing a game tree to improve my guessing because the best guess may not result in the chance of solving the puzzle (see examples on Reddit). There is someone (BinaryChop) who has the created a solver with the following win probabilities as shown on the link below:
expert 53.3% (50,000 samples) starting at 3,3
intermediate 88.9% (50,000 samples) starting at 3,3
beginner 97.224% (200,000 samples) starting at 2,2
I am not there yet but I am now getting close to these numbers.
LikeLike
The link seems to have been lost:
LikeLike
Hey. Thanks for sharing this, it is amazing.
I have one question for this algorithm. For the recurse method, you use the total number of mine as the flag to end the recursion. Why? I mean if just a few cells covered in the grid, we can use the recursion method to give the potential solutions for all the cells unopened. But if we just pass a small border tiles (just a small part of the whole grid), how can we use the total number of mine to be the flag to end the recursion.
LikeLike
Pingback: A Rather Excellent Minesweeper AI – Yujin's TidBits
Hey, that was amazing, but do you think that minesweeper can work with combination Bayes-theorem and best first search algorithm.
LikeLike
Thanks for the explanation, but I like to play online like here: https://mines.zone
LikeLike
Hi I love to continue this mail if I get a response that you see this message I will love to develop an AI project for a new Minegame
LikeLike